
AI-powered speech translation has mainly focused on written languages, yet nearly 3,500 living languages are primarily spoken and don’t have a widely used writing system. This makes it impossible to build machine translation tools using standard techniques, which require large amounts of written text in order to train an AI model.
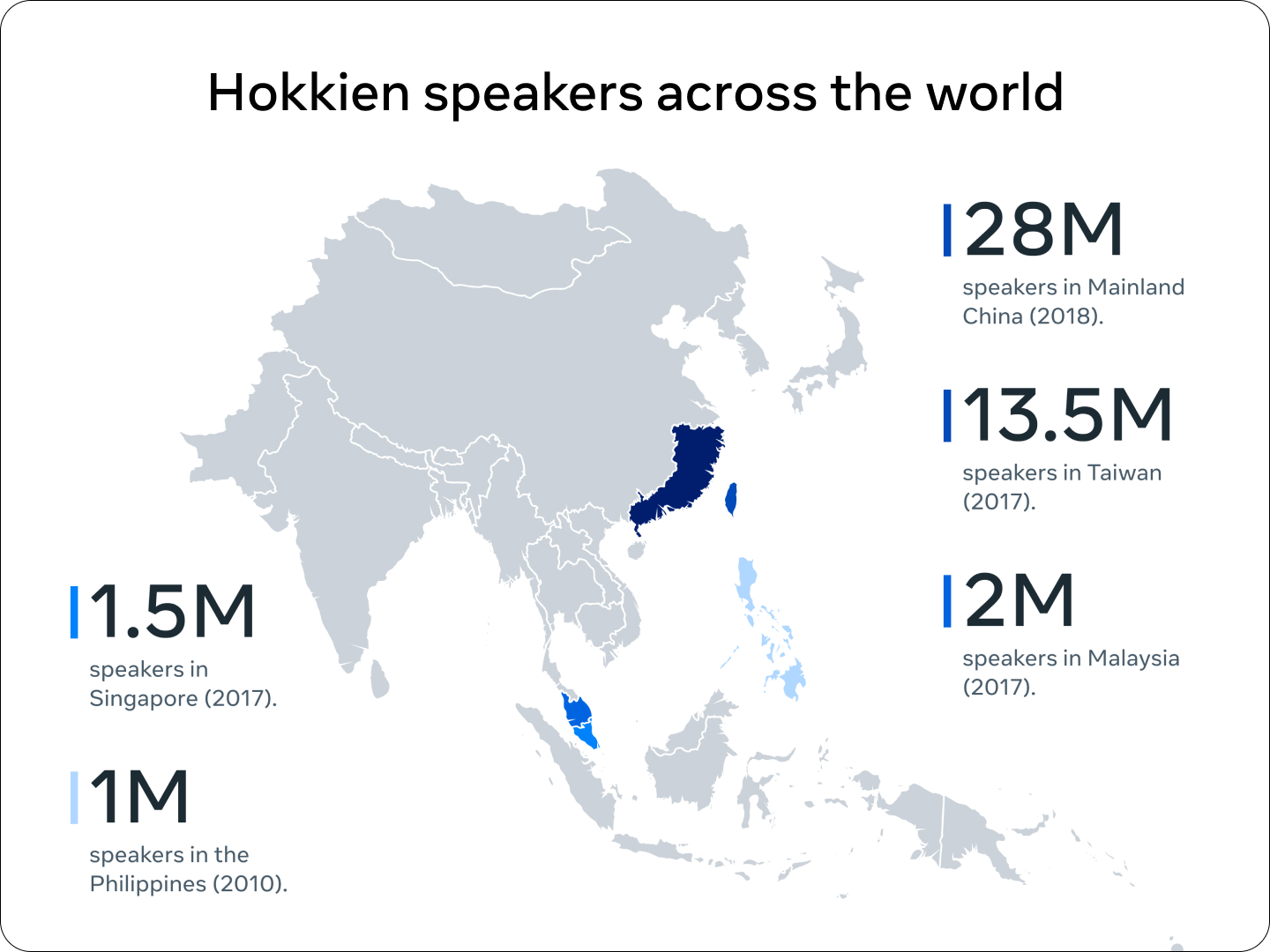
To address this challenge, we’ve built the first AI-powered speech-to-speech translation system for Hokkien, a primarily oral language that’s widely spoken within the Chinese diaspora but lacks a standard written form. We’re open-sourcing our Hokkien translation models, evaluation datasets and research papers so that others can reproduce and build on our work.
The translation system is part of our Universal Speech Translator project, which is developing new AI methods that we hope will eventually allow real-time speech-to-speech translation across many languages. We believe spoken communication can bring people together wherever they are located — even in the metaverse.
A New Modeling Approach
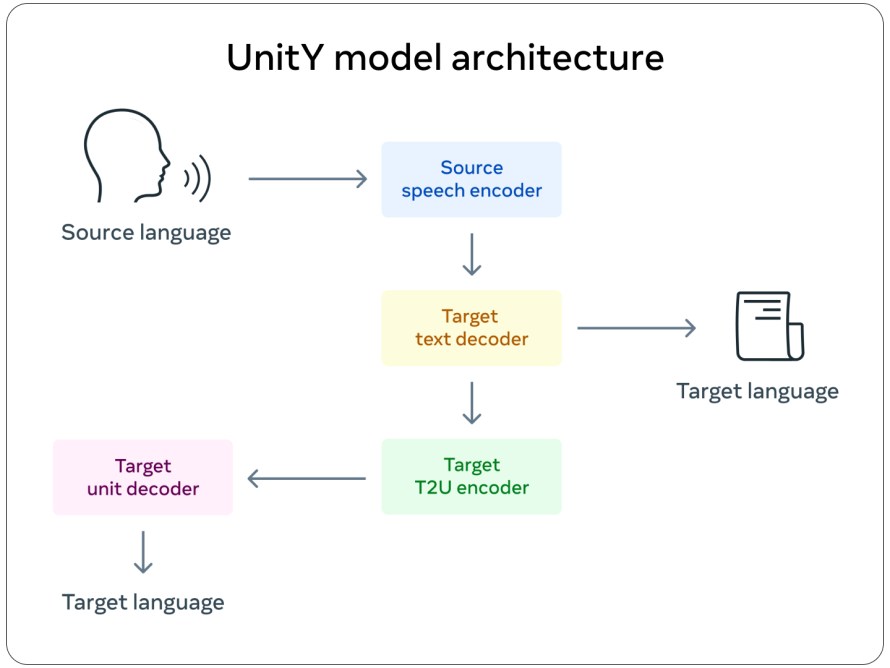
Many speech translation systems rely on transcriptions. However, since primarily oral languages don’t have standard written forms, producing transcribed text as the translation output doesn’t work. So, we focused on speech-to-speech translation.
To do this, we developed a variety of methods, such as using speech-to-unit translation to translate input speech to a sequence of acoustic sounds, and generated waveforms from them or rely on text from a related language, in this case Mandarin.
Looking to the Future of Translation
While the Hokkien translation model is still a work in progress and can translate only one full sentence at a time, it’s a step toward a future where simultaneous translation between languages is possible. The techniques we pioneered can be extended to many other written and unwritten languages.
We’re also releasing SpeechMatrix, which is a large collection of speech-to-speech translations developed through our innovative natural language processing toolkit called LASER. These tools will enable other researchers to create their own speech-to-speech translation systems and build on our work. And our progress in what researchers refer to as unsupervised learning demonstrates the feasibility of building high-quality speech-to-speech translation models without any human annotations. This will help extend those models to work for languages where there isn’t any labeled training data available to train the system.
Our AI research is helping break down language barriers in both the physical world and the metaverse to encourage connection and mutual understanding. We look forward to expanding our research and bringing this technology to more people in the future.
Learn more about our AI-powered speech translation.
