
Supporting Thousands of Languages
Many of the world’s languages are in danger of disappearing, and the limitations of current speech recognition and generation technology will only accelerate this trend. We want to make it easier for people to access information and use devices in their preferred language, and today we’re announcing a series of artificial intelligence (AI) models that could help them do just that.
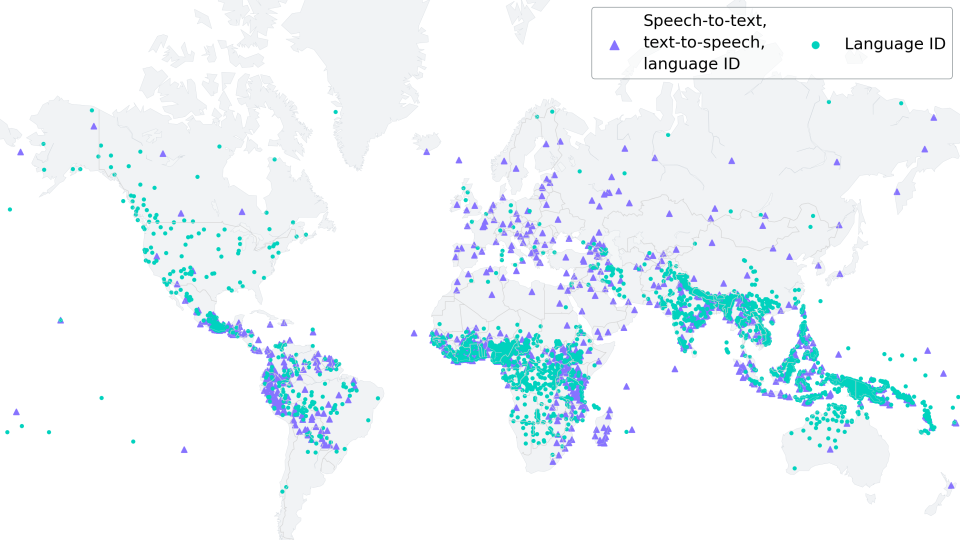
Massively Multilingual Speech (MMS) models expand text-to-speech and speech-to-text technology from around 100 languages to more than 1,100 — more than 10 times as many as before — and can also identify more than 4,000 spoken languages, 40 times more than before.
There are also many use cases for speech technology — from virtual and augmented reality technology to messaging services — that can be used in a person’s preferred language and can understand everyone’s voice.
We’re open-sourcing our models and code so that others in the research community can build on our work and help preserve the world’s languages and bring the world closer together.
Our Approach
Collecting audio data for thousands of languages was our first challenge because the largest existing speech datasets cover 100 languages at most. To overcome this, we turned to religious texts, such as the Bible, that have been translated in many different languages and whose translations have been widely studied for text-based language translation research.
These translations have publicly available audio recordings of people reading these texts in different languages. As part of the MMS project, we created a dataset of readings of the New Testament in more than 1,100 languages, which provided on average 32 hours of data per language.
By considering unlabeled recordings of various other Christian religious readings, we increased the number of languages available to more than 4,000. While this data is from a specific domain and is often read by male speakers, our analysis shows that our models perform equally well for male and female voices. And while the content of the audio recordings is religious, our analysis shows that this doesn’t bias the model to produce more religious language.
Going Forward
In the future, we want to increase MMS’s coverage to support even more languages, and also tackle the challenge of handling dialects, which is often difficult for existing speech technology.
Learn more about MMS.

