
As part of an ongoing series about addressing data misuse, we recently shared an update on how our External Data Misuse (EDM) team works to safeguard people against clone sites. Today, we’re detailing our approach on deterring scraping of Facebook Identifiers (FBIDs) on Facebook.
What Is an Identifier?
Most companies use unique identifiers within the URLs of their website. Identifiers are a way to uniquely reference people or content such as posts, pictures and videos. Within Facebook, these identifiers are known as FBIDs and we use them to load content for people.
Scraping is the automated collection of data from a website or app and can be both authorized and unauthorized. Unauthorized scraping often involves guessing identifiers, or using purchased identifiers to scrape people’s data. In some cases, scrapers collect identifiers and cross-reference phone numbers or other publicly-available data to create reusable data sets that are sometimes sold for profit.
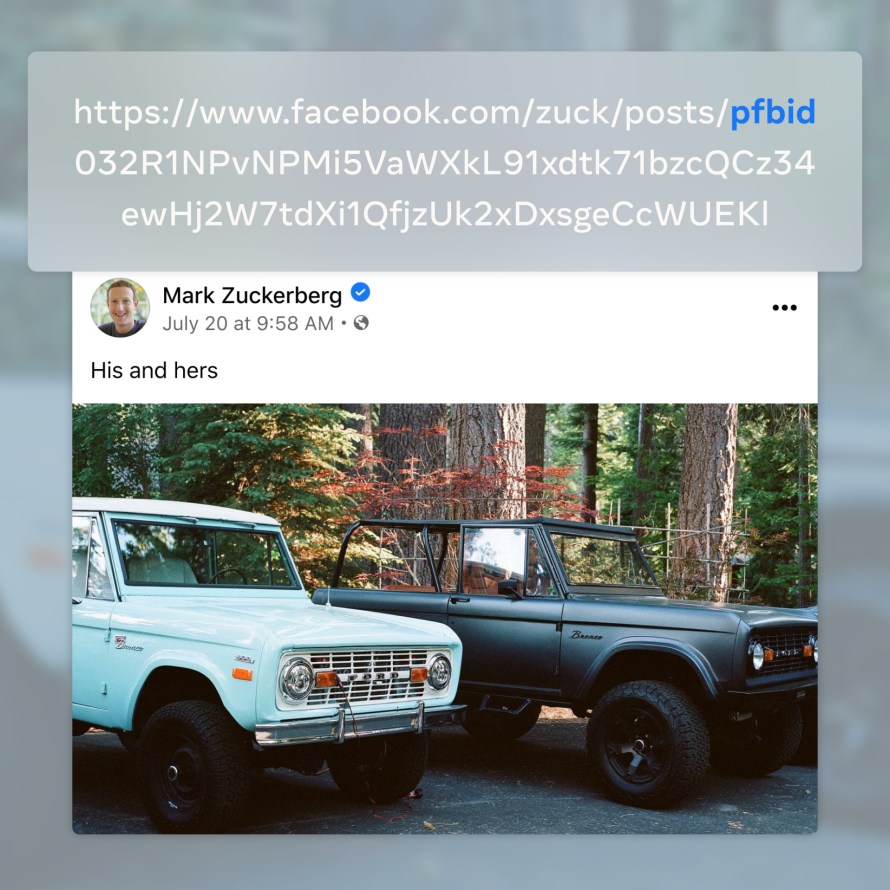
We created Pseudonymized Facebook Identifiers (PFBIDs), which combine timestamps and FBIDs to generate a unique time-rotating identifier. As we phase out the ability to access the original identifiers, this helps deter unauthorized data scraping by making it harder for attackers to guess, connect and repeatedly access data.
These identifiers are not designed to prevent browser tools from removing tracking components from the URL. We use this process to better protect people’s privacy from certain types of enumeration and time-delayed attacks while preserving the ability to have long-lived links.
You can read additional updates and insights on our privacy initiatives on our Privacy Matters page.

