
[]

Last AWS re:Invent, we announced the general availability of Amazon EMR on Amazon Elastic Kubernetes Service (Amazon EKS), a new deployment option for Amazon EMR that allows customers to automate the provisioning and management of Apache Spark on Amazon EKS.
With Amazon EMR on EKS, customers can deploy EMR applications on the same Amazon EKS cluster as other types of applications, which allows them to share resources and standardize on a single solution for operating and managing all their applications. Customers running Apache Spark on Kubernetes can migrate to EMR on EKS and take advantage of the performance-optimized runtime, integration with Amazon EMR Studio for interactive jobs, integration with Apache Airflow and AWS Step Functions for running pipelines, and Spark UI for debugging.
When customers submit jobs, EMR automatically packages the application into a container with the big data framework and provides prebuilt connectors for integrating with other AWS services. EMR then deploys the application on the EKS cluster and manages running the jobs, logging, and monitoring. If you currently run Apache Spark workloads and use Amazon EKS for other Kubernetes-based applications, you can use EMR on EKS to consolidate these on the same Amazon EKS cluster to improve resource utilization and simplify infrastructure management.
Developers who run containerized, big data analytical workloads told us they just want to point to an image and run it. Currently, EMR on EKS dynamically adds externally stored application dependencies during job submission.
Today, I am happy to announce customizable image support for Amazon EMR on EKS that allows customers to modify the Docker runtime image that runs their analytics application using Apache Spark on your EKS cluster.
With customizable images, you can create a container that contains both your application and its dependencies, based on the performance-optimized EMR Spark runtime, using your own continuous integration (CI) pipeline. This reduces the time to build the image and helps predicting container launches for a local development or test.
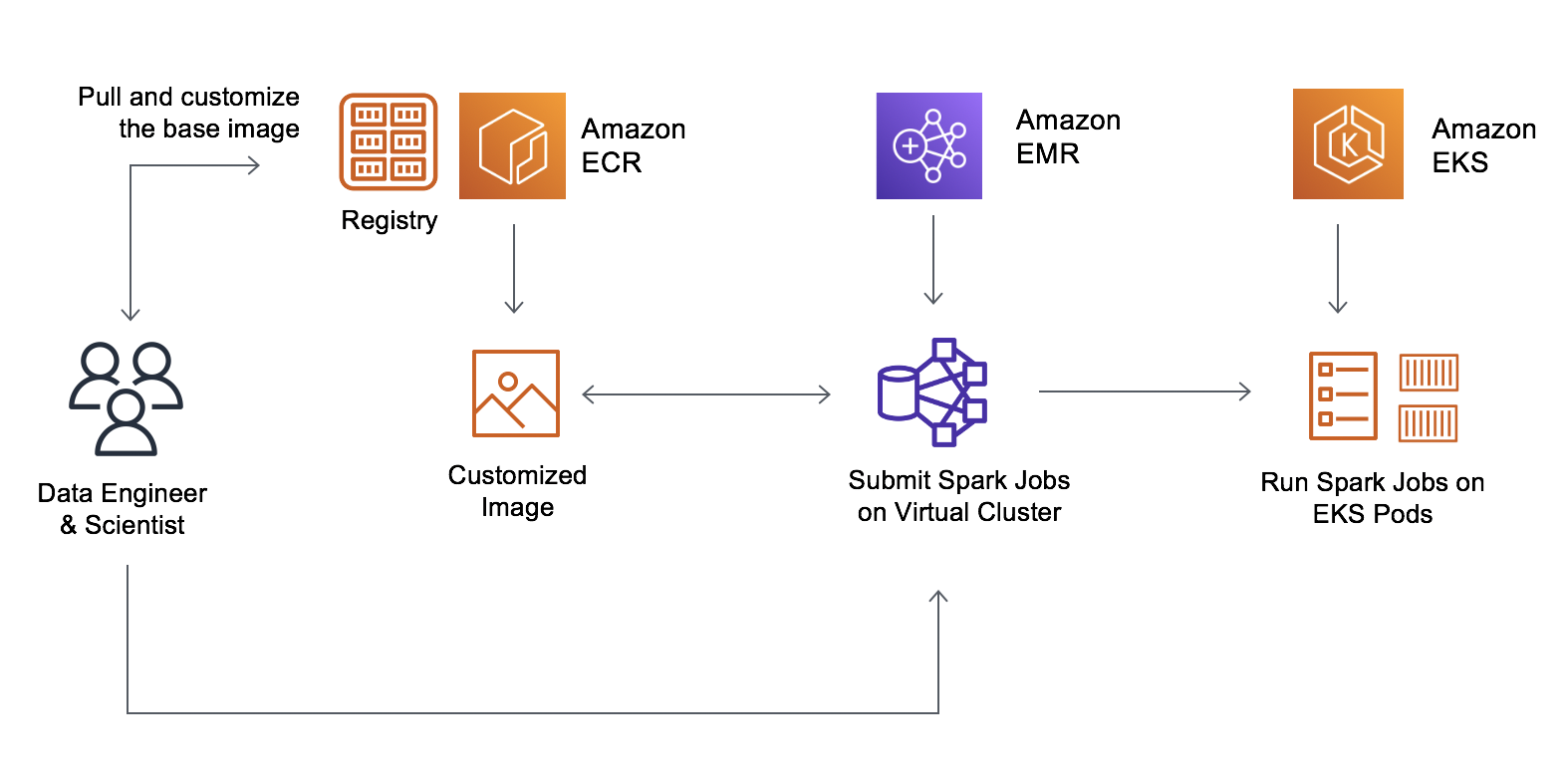
Now, data engineers and platform teams can create a base image, add their corporate standard libraries, and then store it in Amazon Elastic Container Registry (Amazon ECR). Data scientists can customize the image to include their application specific dependencies. The resulting immutable image can be vulnerability scanned, deployed to test and production environments. Developers can now simply point to the customized image and run it on EMR on EKS.
Customizable Runtime Images – Getting Started
To get started with customizable images, use the AWS Command Line Interface (AWS CLI) to perform these steps:
- Register your EKS cluster with Amazon EMR.
- Download the EMR-provided base images from Amazon ECR and modify the image with your application and libraries.
- Publish your customized image to a Docker registry such as Amazon ECR and then submit your job while referencing your image.
You can download one of the following base images. These images contain the Spark runtime that can be used to run batch workloads using the EMR Jobs API. Here is the latest full image list available.
[]
These base images are located in an Amazon ECR repository in each AWS Region with an image URI that combines the ECR registry account, AWS Region code, and base image tag in the case of US East (N. Virginia) Region.
755674844232.dkr.ecr.us-east-1.amazonaws.com/spark/emr-5.32.0-20210129
Now, sign in to the Amazon ECR repository and pull the image into your local workspace. If you want to pull an image from a different AWS Region to reduce network latency, choose the different ECR repository that corresponds most closely to where you are pulling the image from US West (Oregon) Region.
$ aws ecr get-login-password –region us-west-2 | docker login –username AWS –password-stdin 895885662937.dkr.ecr.us-west-2.amazonaws.com $ docker pull 895885662937.dkr.ecr.us-west-2.amazonaws.com/spark/emr-5.32.0-20210129
Create a Dockerfile on your local workspace with the EMR-provided base image and add commands to customize the image. If the application requires custom Java SDK, Python, or R libraries, you can add them to the image directly, just as with other containerized applications.
The following example Docker commands are for a use case in which you want to install useful Python libraries such as Natural Language Processing (NLP) using Spark and Pandas.
FROM 895885662937.dkr.ecr.us-west-2.amazonaws.com/spark/emr-5.32.0-20210129 USER root ### Add customizations here #### RUN pip3 install pyspark pandas spark-nlp // Install Python NLP Libraries USER hadoop:hadoop
In another use case, as I mentioned, you can install a different version of Java (for example, Java 11):
FROM 895885662937.dkr.ecr.us-west-2.amazonaws.com/spark/emr-5.32.0-20210129 USER root ### Add customizations here #### RUN yum install -y java-11-amazon-corretto // Install Java 11 and set home ENV JAVA_HOME /usr/lib/jvm/java-11-amazon-corretto.x86_64 USER hadoop:hadoop
If you’re changing Java version to 11, then you also need to change Java Virtual Machine (JVM) options for Spark. Provide the following options in applicationConfiguration when you submit jobs. You need these options because Java 11 does not support some Java 8 JVM parameters.
“applicationConfiguration”: [ { “classification”: “spark-defaults”, “properties”: { “spark.driver.defaultJavaOptions” : ” -XX:OnOutOfMemoryError=’kill -9 %p’ -XX:MaxHeapFreeRatio=70″, “spark.executor.defaultJavaOptions” : ” -verbose:gc -Xlog:gc*::time -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:OnOutOfMemoryError=’kill -9 %p’ -XX:MaxHeapFreeRatio=70 -XX:+IgnoreUnrecognizedVMOptions” } } ]
To use custom images with EMR on EKS, publish your customized image and submit a Spark workload in Amazon EMR on EKS using the available Spark parameters.
You can submit batch workloads using your customized Spark image. To submit batch workloads using the StartJobRun API or CLI, use the spark.kubernetes.container.image parameter.
$ aws emr-containers start-job-run –virtual-cluster-id
Use the kubectl command to confirm the job is running your custom image.
$ kubectl get pod -n
Get the image for the main container in the Driver pod (Uses jq).
$ kubectl get pod/
To view jobs in the Amazon EMR console, under EMR on EKS, choose Virtual clusters. From the list of virtual clusters, select the virtual cluster for which you want to view logs. On the Job runs table, select View logs to view the details of a job run.

Automating Your CI Process and Workflows
You can now customize an EMR-provided base image to include an application to simplify application development and management. With custom images, you can add the dependencies using your existing CI process, which allows you to create a single immutable image that contains the Spark application and all of its dependencies.
You can apply your existing development processes, such as vulnerability scans against your Amazon EMR image. You can also validate for correct file structure and runtime versions using the EMR validation tool, which can be run locally or integrated into your CI workflow.
The APIs for Amazon EMR on EKS are integrated with orchestration services like AWS Step Functions and AWS Managed Workflows for Apache Airflow (MWAA), allowing you to include EMR custom images in your automated workflows.
Now Available
You can now set up customizable images in all AWS Regions where Amazon EMR on EKS is available. There is no additional charge for custom images. To learn more, see the Amazon EMR on EKS Development Guide and a demo video how to build your own images for running Spark jobs on Amazon EMR on EKS.
You can send feedback to the AWS forum for Amazon EMR or through your usual AWS support contacts.
— Channy

