
 |
Last year at re:Invent, we introduced the preview of Amazon Redshift Serverless, a serverless option of Amazon Redshift that lets you analyze data at any scale without having to manage data warehouse infrastructure. You just need to load and query your data, and you pay only for what you use. This allows more companies to build a modern data strategy, especially for use cases where analytics workloads are not running 24-7 and the data warehouse is not active all the time. It is also applicable to companies where the use of data expands within the organization and users in new departments want to run analytics without having to take ownership of data warehouse infrastructure.
Today, I am happy to share that Amazon Redshift Serverless is generally available and that we added many new capabilities. We are also reducing Amazon Redshift Serverless compute costs compared to the preview.
You can now create multiple serverless endpoints per AWS account and Region using namespaces and workgroups:
- A namespace is a collection of database objects and users, such as database name and password, permissions, and encryption configuration. This is where your data is managed and where you can see how much storage is used.
- A workgroup is a collection of compute resources, including network and security settings. Each workgroup has a serverless endpoint to which you can connect your applications. When configuring a workgroup, you can set up private or publicly accessible endpoints.
Each namespace can have only one workgroup associated with it. Conversely, each workgroup can be associated with only one namespace. You can have a namespace without any workgroup associated with it, for example, to use it only for sharing data with other namespaces in the same or another AWS account or Region.
In your workgroup configuration, you can now use query monitoring rules to help keep your costs under control. Also, the way Amazon Redshift Serverless automatically scales data warehouse capacity is more intelligent to deliver fast performance for demanding and unpredictable workloads.
Let’s see how this works with a quick demo. Then, I’ll show you what you can do with namespaces and workgroups.
Using Amazon Redshift Serverless
In the Amazon Redshift console, I select Redshift serverless in the navigation pane. To get started, I choose Use default settings to configure a namespace and a workgroup with the most common options. For example, I’ll be able to connect using my default VPC and default security group.

With the default settings, the only option left to configure is Permissions. Here, I can specify how Amazon Redshift can interact with other services such as S3, Amazon CloudWatch Logs, Amazon SageMaker, and AWS Glue. To load data later, I give Amazon Redshift access to an S3 bucket. I choose Manage IAM roles and then Create IAM role.
When creating the IAM role, I select the option to give access to specific S3 buckets and pick an S3 bucket in the same AWS Region. Then, I choose Create IAM role as default to complete the creation of the role and to automatically use it as the default role for the namespace.

I choose Save configuration and after a few minutes the database is ready for use. In the Serverless dashboard, I choose Query data to open the Redshift query editor v2. There, I follow the instructions in the Amazon Redshift Database Developer guide to load a sample database. If you want to do a quick test, a few sample databases (including the one I am using here) are already available in the sample_data_dev database. Note also that loading data into Amazon Redshift is not required for running queries. I can use data from an S3 data lake in my queries by creating an external schema and an external table.
The sample database consists of seven tables and tracks sales activity for a fictional “TICKIT” website, where users buy and sell tickets for sporting events, shows, and concerts.
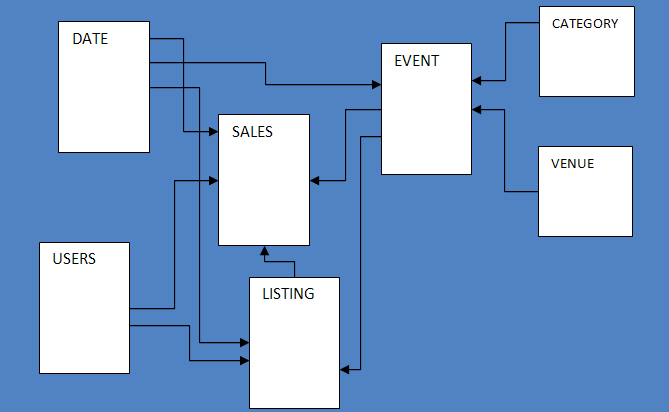
To configure the database schema, I run a few SQL commands to create the users, venue, category, date, event, listing, and sales tables.

Then, I download the tickitdb.zip file that contains the sample data for the database tables. I unzip and load the files to a tickit folder in the same S3 bucket I used when configuring the IAM role.
Now, I can use the COPY command to load the data from the S3 bucket into my database. For example, to load data into the users table:
copy users from ‘s3://MYBUCKET/tickit/allusers_pipe.txt’ iam_role default;
The file containing the data for the sales table uses tab-separated values:
copy sales from ‘s3://MYBUCKET/tickit/sales_tab.txt’ iam_role default delimiter ‘t’ timeformat ‘MM/DD/YYYY HH:MI:SS’;
After I load data in all tables, I start running some queries. For example, the following query joins five tables to find the top five sellers for events based in California (note that the sample data is for the year 2008):
select sellerid, username, (firstname ||’ ‘|| lastname) as sellername, venuestate, sum(qtysold) from sales, date, users, event, venue where sales.sellerid = users.userid and sales.dateid = date.dateid and sales.eventid = event.eventid and event.venueid = venue.venueid and year = 2008 and venuestate = ‘CA’ group by sellerid, username, sellername, venuestate order by 5 desc limit 5;

Now that my database is ready, let’s see what I can do by configuring Amazon Redshift Serverless namespaces and workgroups.
Using and Configuring Namespaces
Namespaces are collections of database data and their security configurations. In the navigation pane of the Amazon Redshift console, I choose Namespace configuration. In the list, I choose the default namespace that I just created.
In the Data backup tab, I can create or restore a snapshot or restore data from one of the recovery points that are automatically created every 30 minutes and kept for 24 hours. That can be useful to recover data in case of accidental writes or deletes.

In the Security and encryption tab, I can update permissions and encryption settings, including the AWS Key Management Service (AWS KMS) key used to encrypt and decrypt my resources. In this tab, I can also enable audit logging and export the user, connection, and user activity logs to CloudWatch Logs.

In the Datashares tab, I can create a datashare to share data with other namespaces and AWS accounts in the same or different Regions. In this tab, I can also create a database from a share I receive from other namespaces or AWS accounts, and I can see the subscriptions for datashares managed by AWS Data Exchange.

When I create a datashare, I can select which objects to include. For example, here I want to share only the date and event tables because they don’t contain sensitive data.

Using and Configuring Workgroups
Workgroups are collections of compute resources and their network and security settings. They provide the serverless endpoint for the namespace they are configured for. In the navigation pane of the Amazon Redshift console, I choose Workgroup configuration. In the list, I choose the default namespace that I just created.
In the Data access tab, I can update the network and security settings (for example, change the VPC, the subnets, or the security group) or make the endpoint publicly accessible. In this tab, I can also enable Enhanced VPC routing to route network traffic between my serverless database and the data repositories I use (for example, the S3 buckets used to load or unload data) through a VPC instead of the internet. To access serverless endpoints that are in another VPC or subnet, I can create a VPC endpoint managed by Amazon Redshift.

In the Limits tab, I can configure the base capacity (expressed in Redshift processing units, or RPUs) used to process my queries. Amazon Redshift Serverless scales the capacity to deal with a higher number of users. Here I also have the option to increase the base capacity to speed up my queries or decrease it to reduce costs.
In this tab, I can also set Usage limits to configure daily, weekly, and monthly thresholds to keep my costs predictable. For example, I configured a daily limit of 200 RPU-hours, and a monthly limit of 2,000 RPU-hours for my compute resources. To control the data-transfer costs for cross-Region datashares, I configured a daily limit of 3 TB and a weekly limit of 10 TB. Finally, to limit the resources used by each query, I use Query limits to time out queries running for more than 60 seconds.

Availability and Pricing
Amazon Redshift Serverless is generally available today in the US East (Ohio), US East (N. Virginia), US East (Oregon), Europe (Frankfurt), Europe (Ireland), Europe (London), Europe (Stockholm), and Asia Pacific (Seoul), Asia Pacific (Singapore), Asia Pacific (Sydney), and Asia Pacific (Tokyo) AWS Regions.
You can connect to a workgroup endpoint using your favorite client tools via JDBC/ODBC or with the Amazon Redshift query editor v2, a web-based SQL client application available on the Amazon Redshift console. When using web services-based applications (such as AWS Lambda functions or Amazon SageMaker notebooks), you can access your database and perform queries using the built-in Amazon Redshift Data API.
With Amazon Redshift Serverless, you pay only for the compute capacity your database consumes when active. The compute capacity scales up or down automatically based on your workload and shuts down during periods of inactivity to save time and costs. Your data is stored in managed storage, and you pay a GB-month rate.
To give you improved price performance and the flexibility to use Amazon Redshift Serverless for an even broader set of use cases, we are lowering the price from $0.5 to $0.375 per RPU-hour for the US East (N. Virginia) Region. Similarly, we are lowering the price in other Regions by an average of 25 percent from the preview price. For more information, see the Amazon Redshift pricing page.
To help you get practice with your own use cases, we are also providing $300 in AWS credits for 90 days to try Amazon Redshift Serverless. These credits are used to cover your costs for compute, storage, and snapshot usage of Amazon Redshift Serverless only.
Get insights from your data in seconds with Amazon Redshift Serverless.
— Danilo

