
 |
Today we are making Amazon MSK Serverless generally available to help you reduce even more the operational overhead of managing an Apache Kafka cluster by offloading the capacity planning and scaling to AWS.
In May 2019, we launched Amazon Managed Streaming for Apache Kafka to help our customers stream data using Apache Kafka. Apache Kafka is an open-source platform that enables customers to capture streaming data like clickstream events, transactions, and IoT events. Apache Kafka is a common solution for decoupling applications that produce streaming data (producers) from those consuming the data (consumers). Amazon MSK makes it easy to ingest and process streaming data in real time with fully managed Apache Kafka clusters.
Amazon MSK reduces the work needed to set up, scale, and manage Apache Kafka in production. With Amazon MSK, you can create a cluster in minutes and start sending data. Apache Kafka runs as a cluster on one or more brokers. Brokers are instances with a given compute and storage capacity distributed in multiple AWS Availability Zones to create high availability. Apache Kafka stores records on topics for a user-defined period of time, partitions those topics, and then replicates these partitions across multiple brokers. Data producers write records to topics, and consumers read records from them.
When creating a new Amazon MSK cluster, you need to decide the number of brokers, the size of the instances, and the storage that each broker has available. The performance of an MSK cluster depends on these parameters. These settings can be easy to provide if you already know the workload. But how will you configure an Amazon MSK cluster for a new workload? Or for an application that has variable or unpredictable data traffic?
Amazon MSK Serverless
Amazon MSK Serverless automatically provisions and manages the required resources to provide on-demand streaming capacity and storage for your applications. It is the perfect solution to get started with a new Apache Kafka workload where you don’t know how much capacity you will need or if your applications produce unpredictable or highly variable throughput and you don’t want to pay for idle capacity. Also, it is great if you want to avoid provisioning, scaling, and managing resource utilization of your clusters.
Amazon MSK Serverless comes with a lot of secure features out of the box, such as private connectivity. This means that the traffic doesn’t leave the AWS backbone, AWS Identity and Access Management (IAM) access control, and encryption of your data at rest and in transit, which keeps it secure.
An Amazon MSK Serverless cluster scales capacity up and down instantly based on the application requirements. When Apache Kafka clusters are scaled horizontally (that is, more brokers are added), you also need to move partitions to these new brokers to make use of the added capacity. With Amazon MSK Serverless, you don’t need to scale brokers or do partition movement.
Each Amazon MSK Serverless cluster provides up to 200 MBps of write-throughput and 400 MBps of read-throughput. It also allocates up to 5 MBps of write-throughput and 10 MBps of read-throughput per partition.
Amazon MSK Serverless pricing is based on throughput. You can learn more on the MSK’s pricing page.
Let’s see it in action
Imagine that you are the architect of a mobile game studio, and you are about to launch a new game. You invested in the game’s marketing, and you expect it will have a lot of new players. Your games send clickstream data to your backend application. The data is analyzed in real time to produce predictions on your players’ behaviors. With these predictions, your games make real-time offers that suit the current player’s behavior, encouraging them to stay in the game longer.
Your games send clickstream data to an Apache Kafka cluster. As you are using an Amazon MSK Serverless cluster, you don’t need to worry about scaling the cluster when the new game launches, as it will adjust its capacity to the throughput.
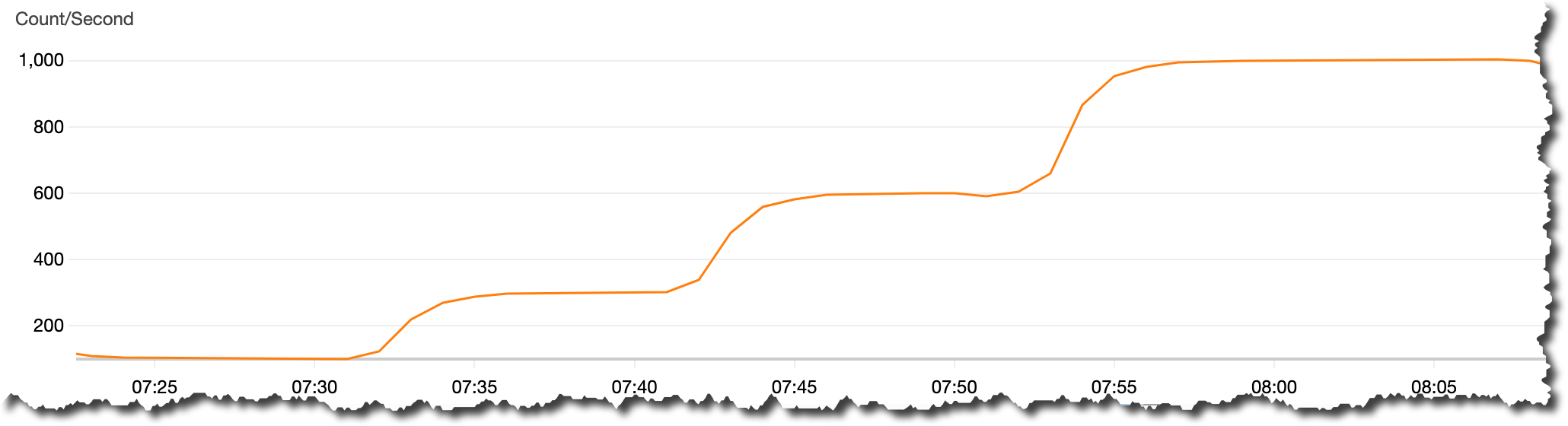
In the following image, you can see a graph of the day of the launch of the new game. It shows in orange the metric MessagesInPerSec that the cluster is consuming. And you can see that the number of messages per second is increasing first from 100, which is our base number before the launch. Then it increases to 300, 600, and 1,000 messages per second, as our game is getting downloaded and played by more and more players. You can feel confident that the volume of records can keep increasing. Amazon MSK Serverless is capable of ingesting all the records as long as your application throughput stays within the service limits.
How to get started with Amazon MSK Serverless
Creating an Amazon MSK Serverless cluster is very simple, as you don’t need to provide any capacity configuration to the service. You can create a new cluster on the Amazon MSK console page.
Choose the Quick create cluster creation method. This method will provide you with the best-practice settings to create a starter cluster and input a name for your cluster.
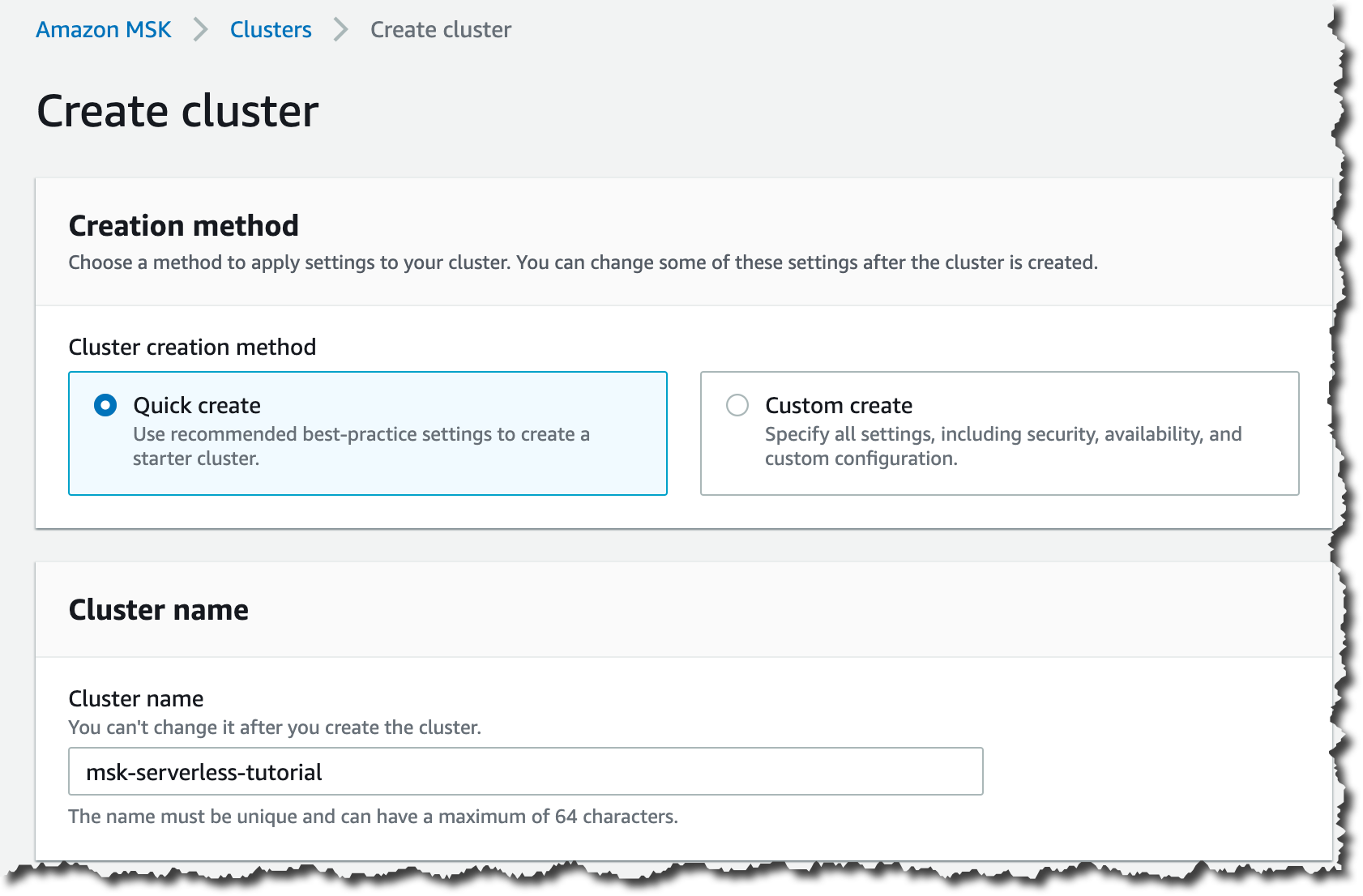
Then, in the General cluster properties, choose the cluster type. Choose the Serverless option to create an Amazon MSK Serverless cluster.

Finally, it shows all the cluster settings that it will configure by default. You cannot change most of these settings after the cluster is created. If you need different values for these settings, you might need to create the cluster using the Custom create method. If the default settings work for you, then create the cluster.

Creating the cluster will take you a few minutes, and after that, you see the Active status on the Cluster summary page.
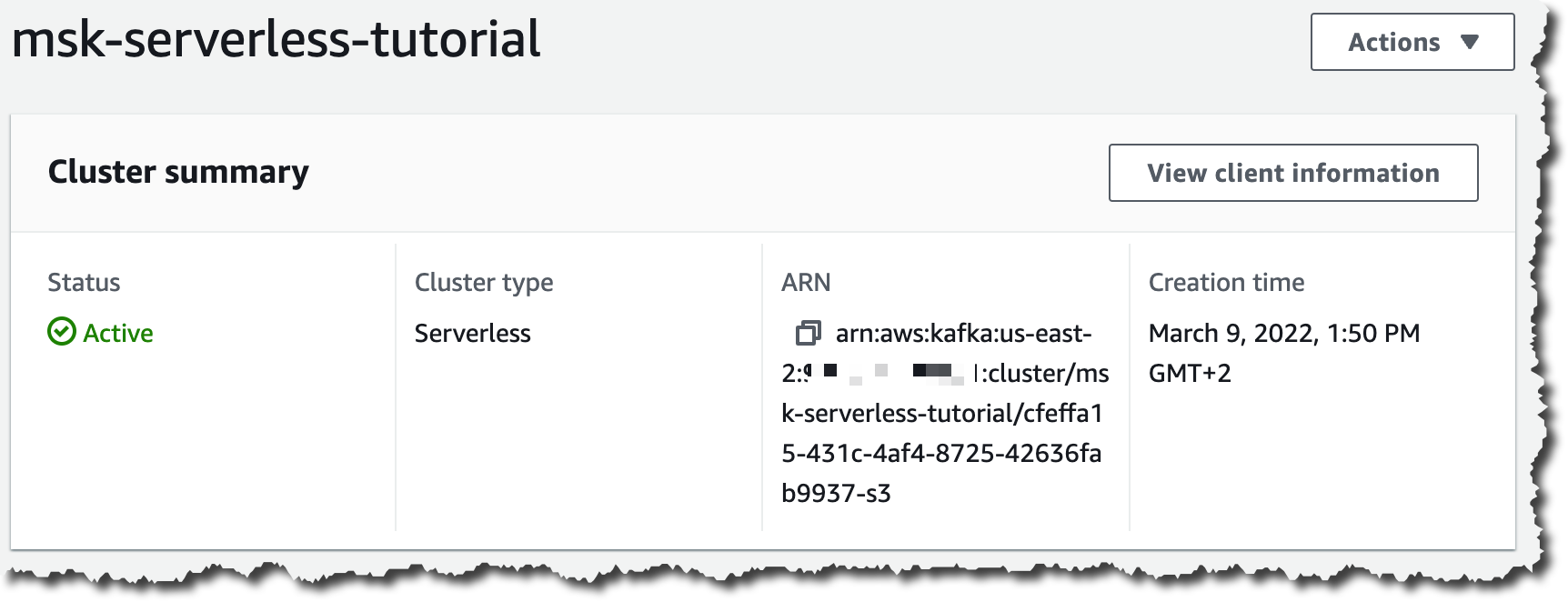
Now that you have the cluster, you can start sending and receiving records using an Amazon Elastic Compute Cloud (Amazon EC2) instance. For doing that, the first step is to create a new IAM policy and IAM role. The instances need to authenticate using IAM in order to access the cluster from the instances.
Amazon MSK Serverless integrates with IAM to provide fine-grained access control to your Apache Kafka workloads. You can use IAM policies to grant least privileged access to your Apache Kafka clients.
Create the IAM policy
Create a new IAM policy with the following JSON. This policy will give permissions to connect to the cluster, create a topic, send data, and consume data from the topic.
{ “Version”: “2012-10-17”, “Statement”: [ { “Effect”: “Allow”, “Action”: [ “kafka-cluster:Connect” ], “Resource”: “arn:aws:kafka:
Make sure that you replace the Region and account ID with your own. Also, you need to replace the cluster, topic, and group ARN. To get these ARNs, you can go to the cluster summary page and get the cluster ARN. The topic ARN and the group ARN are based on the cluster ARN. Here, the cluster and the topic are named msk-serverless-tutorial.
“arn:aws:kafka:
Then create a new role with the use case EC2 and attach this policy to the role.

Create a new EC2 instance
Now that you have the cluster and the role, create a new Amazon EC2 instance. Add the instance to the same VPC, subnet, and security group as the cluster. You can find that information on your cluster properties page in the networking settings. Also, when configuring the instance, attach the role that you just created in the previous step.

When you are ready, launch the instance. You are going to use the same instance to produce and consume messages. To do that, you need to set up Apache Kafka client tools in the instance. You can follow the Amazon MSK developer guide to get your instance ready.
Producing and consuming records
Now that you have everything configured, you can start sending and receiving records using Amazon MSK Serverless. The first thing you need to do is to create a topic. From your EC2 instance, go to the directory where you installed the Apache Kafka tools and export the bootstrap server endpoint.
cd kafka_2.13-3.1.0/bin/ export BS=boot-abc1234.c3.kafka-serverless.us-east-2.amazonaws.com:9098
As you are using Amazon MSK Serverless, there is only one address for this server, and you can find it in the client information on your cluster page.

Run the following command to create a topic with the name msk-serverless-tutorial.
./kafka-topics.sh –bootstrap-server $BS –command-config client.properties –create –topic msk-serverless-tutorial –partitions 6
Now you can start sending records. If you want to see the service work under a high throughput, you can use the Apache Kafka producer performance test tool. This tool allows you to send many messages at the same time to the MSK cluster with a defined throughput and specific size. Experiment with this performance test tool, change the number of messages per second and the record size and see how the cluster behaves and adapts its capacity.
./kafka-topics.sh –bootstrap-server $BS –command-config client.properties –create –topic msk-serverless-tutorial –partitions 6
Finally, if you want to receive the messages, open a new terminal, connect to the same EC2 instance, and use the Apache Kafka consumer tool to receive the messages.
cd kafka_2.13-3.1.0/bin/ export BS=boot-abc1234.c3.kafka-serverless.us-east-2.amazonaws.com:9098 ./kafka-console-consumer.sh –bootstrap-server $BS –consumer.config client.properties –topic msk-serverless-tutorial –from-beginning
You can see how the cluster is doing on the monitoring page of the Amazon MSK Serverless cluster.

Availability
Amazon MSK Serverless is available in US East (Ohio), US East (N. Virginia), US West (Oregon), Europe (Frankfurt), Europe (Ireland), Europe (Stockholm), Asia Pacific (Singapore), Asia Pacific (Sydney), and Asia Pacific (Tokyo).
Learn more about this service and its pricing on the Amazon MSK Serverless feature page.
– Marcia
