|
Today, we are launching a new reference architecture and a set of reference implementations for enterprise-grade deployment pipelines. A deployment pipeline automates the building, testing, and deploying of applications or infrastructures into your AWS environments. When you deploy your workloads to the cloud, having deployment pipelines is key to gaining agility and lowering time to market.
When I talk with you at conferences or on social media, I frequently hear that our documentation and tutorials are good resources to get started with a new service or a new concept. However, when you want to scale your usage or when you have complex or enterprise-grade use cases, you often lack resources to dive deeper.
This is why we have created over the years hundreds of reference architectures based on real-life use cases and also the security reference architecture. Today, we are adding a new reference architecture to this collection.
We used the best practices and lessons learned at Amazon and with hundreds of customer projects to create this deployment pipeline reference architecture and implementations. They go well beyond the typical “Hello World” example: They document how to architect and how to implement complex deployment pipelines with multiple environments, multiple AWS accounts, multiple Regions, manual approval, automated testing, automated code analysis, etc. When you want to increase the speed at which you deliver software to your customers through DevOps and continuous delivery, this new reference architecture shows you how to combine AWS services to work together. They document the mandatory and optional components of the architecture.
Having an architecture document and diagram is great, but having an implementation is even better. Each pipeline type in the reference architecture has at least one reference implementation. One of the reference implementations uses an AWS Cloud Development Kit (AWS CDK) application to deploy the reference architecture on your accounts. It is a good starting point to study or customize the reference architecture to fit your specific requirements.
You will find this reference architecture and its implementations at https://pipelines.devops.aws.dev.

Let’s Deploy a Reference Implementation
The new deployment pipeline reference architecture demonstrates how to build a pipeline to deploy a Java containerized application and a database. It comes with two reference implementations. We are working on additional pipeline types to deploy Amazon EC2 AMIs, manage a fleet of accounts, and manage dynamic configuration for your applications.
The sample application is developed with SpringBoot. It runs on top of Corretto, the Amazon-provided distribution of the OpenJDK. The application is packaged with the CDK and is deployed on AWS Fargate. But the application is not important here; you can substitute your own application. The important parts are the infrastructure components and the pipeline to deploy an application. For this pipeline type, we provide two reference implementations. One deploys the application using Amazon CodeCatalyst, the new service that we announced at re:Invent 2022, and one uses AWS CodePipeline. This is the one I choose to deploy for this blog post.
The pipeline starts building the applications with AWS CodeBuild. It runs the unit tests and also runs Amazon CodeGuru to review code quality and security. Finally, it runs Trivy to detect additional security concerns, such as known vulnerabilities in the application dependencies. When the build is successful, the pipeline deploys the application in three environments: beta, gamma, and production. It deploys the application in the beta environment in a single Region. The pipeline runs end-to-end tests in the beta environment. All the tests must succeed before the deployment continues to the gamma environment. The gamma environment uses two Regions to host the application. After deployment in the gamma environment, the deployment into production is subject to manual approval. Finally, the pipeline deploys the application in the production environment in six Regions, with three waves of deployments made of two Regions each.
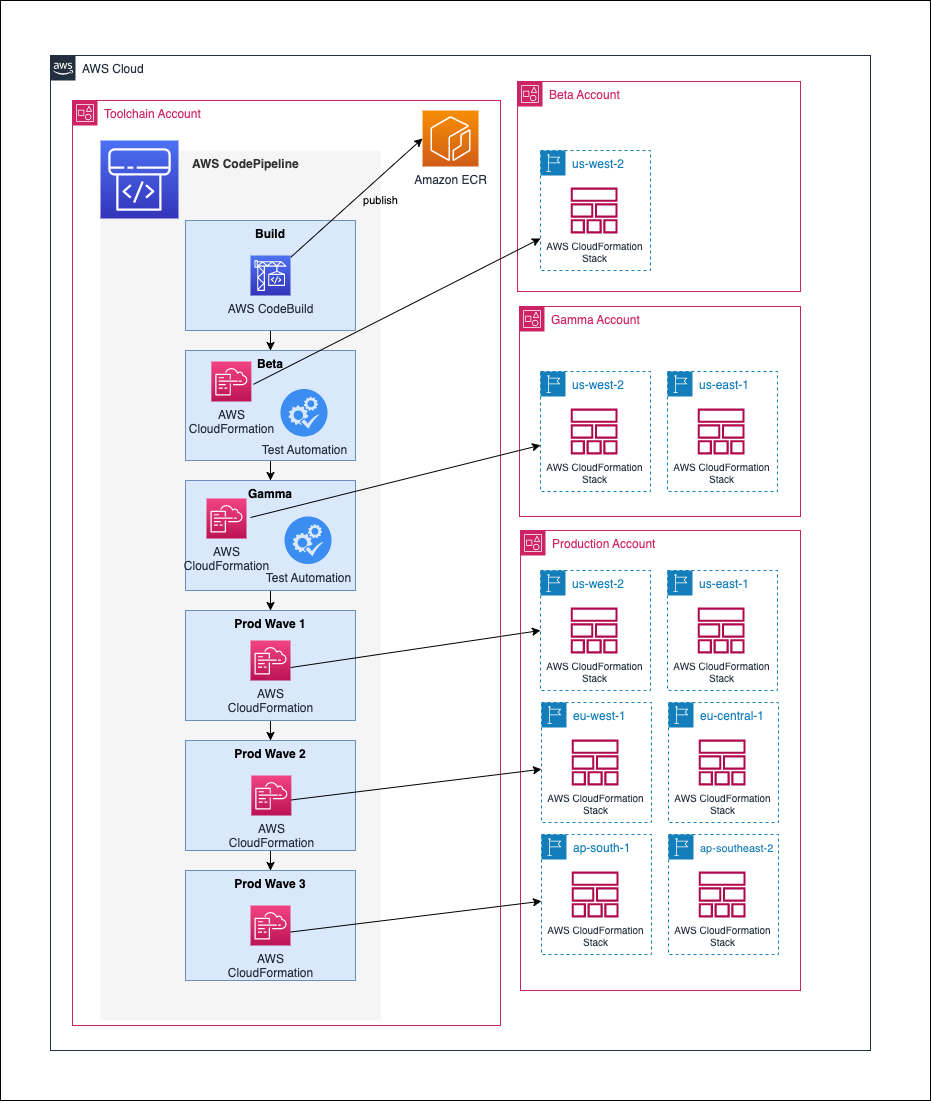
I need four AWS accounts to deploy this reference implementation: one to deploy the pipeline and tooling and one for each environment (beta, gamma, and production). At a high level, there are two deployment steps: first, I bootstrap the CDK for all four accounts, and then I create the pipeline itself in the toolchain account. You must plan for 2-3 hours of your time to prepare your accounts, create the pipeline, and go through a first deployment.
Once the pipeline is created, it builds, tests, and deploys the sample application from its source in AWS CodeCommit. You can commit and push changes to the application source code and see it going through the pipeline steps again.
My colleague Irshad Buch helped me try the pipeline on my account. He wrote a detailed README with step-by-step instructions to let you do the same on your side. The reference architecture that describes this implementation in detail is available on this new web page. The application source code, the AWS CDK scripts to deploy the application, and the AWS CDK scripts to create the pipeline itself are all available on AWS’s GitHub. Feel free to contribute, report issues or suggest improvements.
Available Now
The deployment pipeline reference architecture and its reference implementations are available today, free of charge. If you decide to deploy a reference implementation, we will charge you for the resources it creates on your accounts. You can use the provided AWS CDK code and the detailed instructions to deploy this pipeline on your AWS accounts. Try them today!