|
Today we are announcing a new Amazon Comprehend feature for intelligent document processing (IDP). This feature allows you to classify and extract entities from PDF documents, Microsoft Word files, and images directly from Amazon Comprehend without you needing to extract the text first.
Many customers need to process documents that have a semi-structured format, like images of receipts that were scanned or tax statements in PDF format. Until today, those customers first needed to preprocess those documents to flatten them into machine-readable text, which can reduce the quality of the document context. Then they could use Amazon Comprehend to classify and extract entities from those preprocessed files.
Now with Amazon Comprehend for IDP, customers can process their semi-structured documents, such as PDFs, docx, PNG, JPG, or TIFF images, as well as plain-text documents, with a single API call. This new feature combines OCR and Amazon Comprehend’s existing natural language processing (NLP) capabilities to classify and extract entities from the documents. The custom document classification API allows you to organize documents into categories or classes, and the custom-named entity recognition API allows you to extract entities from documents like product codes or business-specific entities. For example, an insurance company can now process scanned customers’ claims with fewer API calls. Using the Amazon Comprehend entity recognition API, they can extract the customer number from the claims and use the custom classifier API to sort the claim into the different insurance categories—home, car, or personal.
Starting today, Amazon Comprehend for IDP APIs are available for real-time inferencing of files, as well as for asynchronous batch processing on large document sets. This feature simplifies the document processing pipeline and reduces development effort.
Getting Started
You can use Amazon Comprehend for IDP from the AWS Management Console, AWS SDKs, or AWS Command Line Interface (CLI).
In this demo, you will see how to asynchronously process a semi-structured file with a custom classifier. For extracting entities, the steps are different, and you can learn how to do it by checking the documentation.
In order to process a file with a classifier, you will first need to train a custom classifier. You can follow the steps in the Amazon Comprehend Developer Guide. You need to train this classifier with plain text data.
After you train your custom classifier, you can classify documents using either asynchronous or synchronous operations. For using the synchronous operation to analyze a single document, you need to create an endpoint to run real-time analysis using a custom model. You can find more information about real-time analysis in the documentation. For this demo, you are going to use the asynchronous operation, placing the documents to classify in an Amazon Simple Storage Service (Amazon S3) bucket and running an analysis batch job.
To get started classifying documents in batch from the console, on the Amazon Comprehend page, go to Analysis jobs and then Create job.
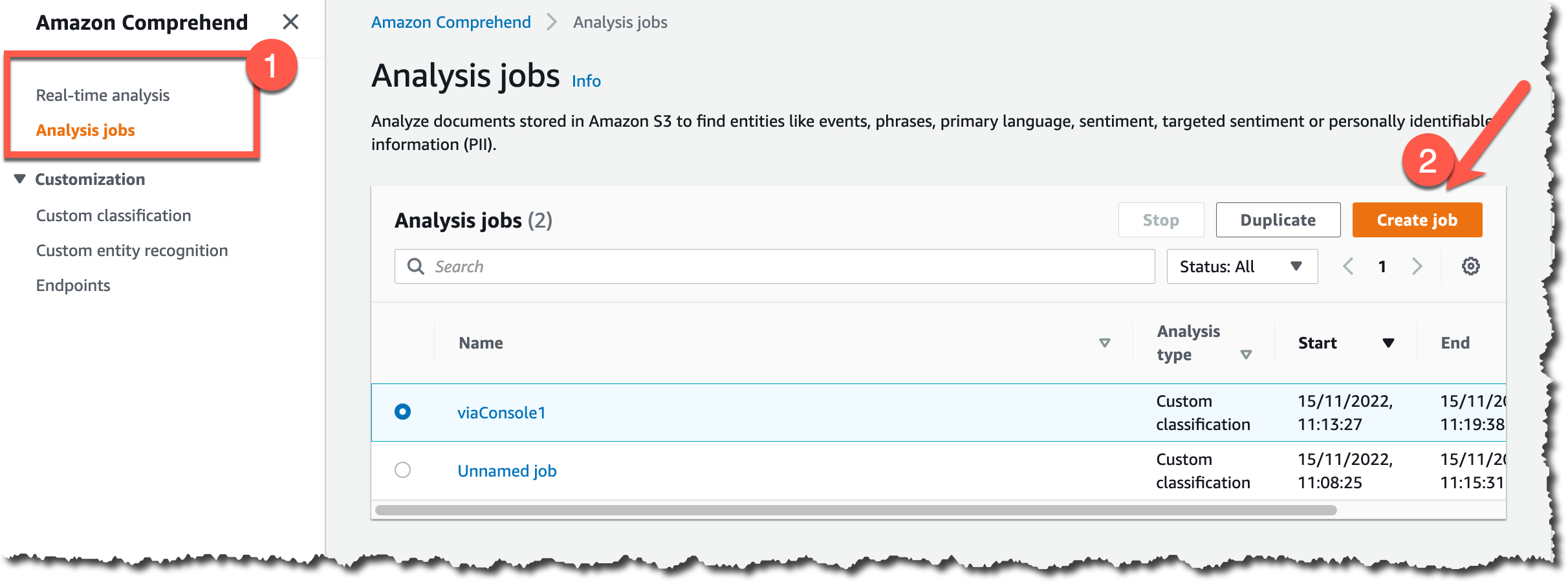
Then you can configure the new analysis job. First, input a name and pick Custom classification and the custom classifier you created earlier.
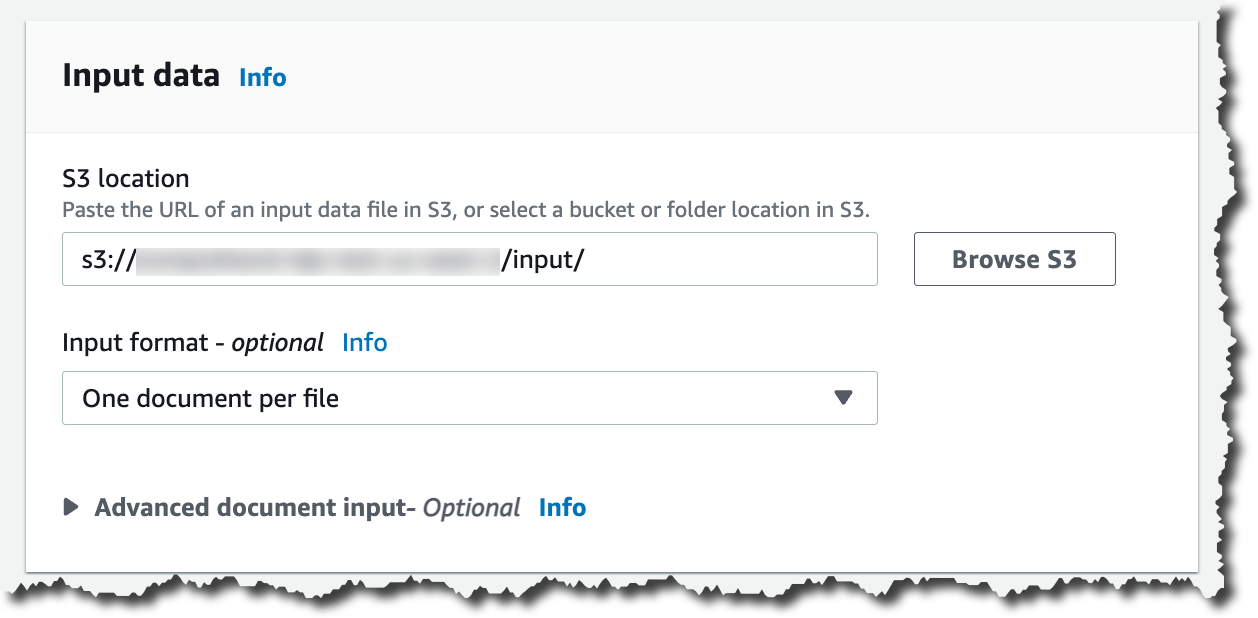
Then you can configure the input data. First, select the S3 location for that data. In that location, you can place your PDFs, images, and Word Documents. Because you are processing semi-structured documents, you need to choose One document per file. If you want to override Amazon Comprehend settings for extracting and parsing the document, you can configure the Advanced document input options.
After configuring the input data, you can select where the output of this analysis should be stored. Also, you need to give access permissions for this analysis job to read and write on the specified Amazon S3 locations, and then you are ready to create the job.
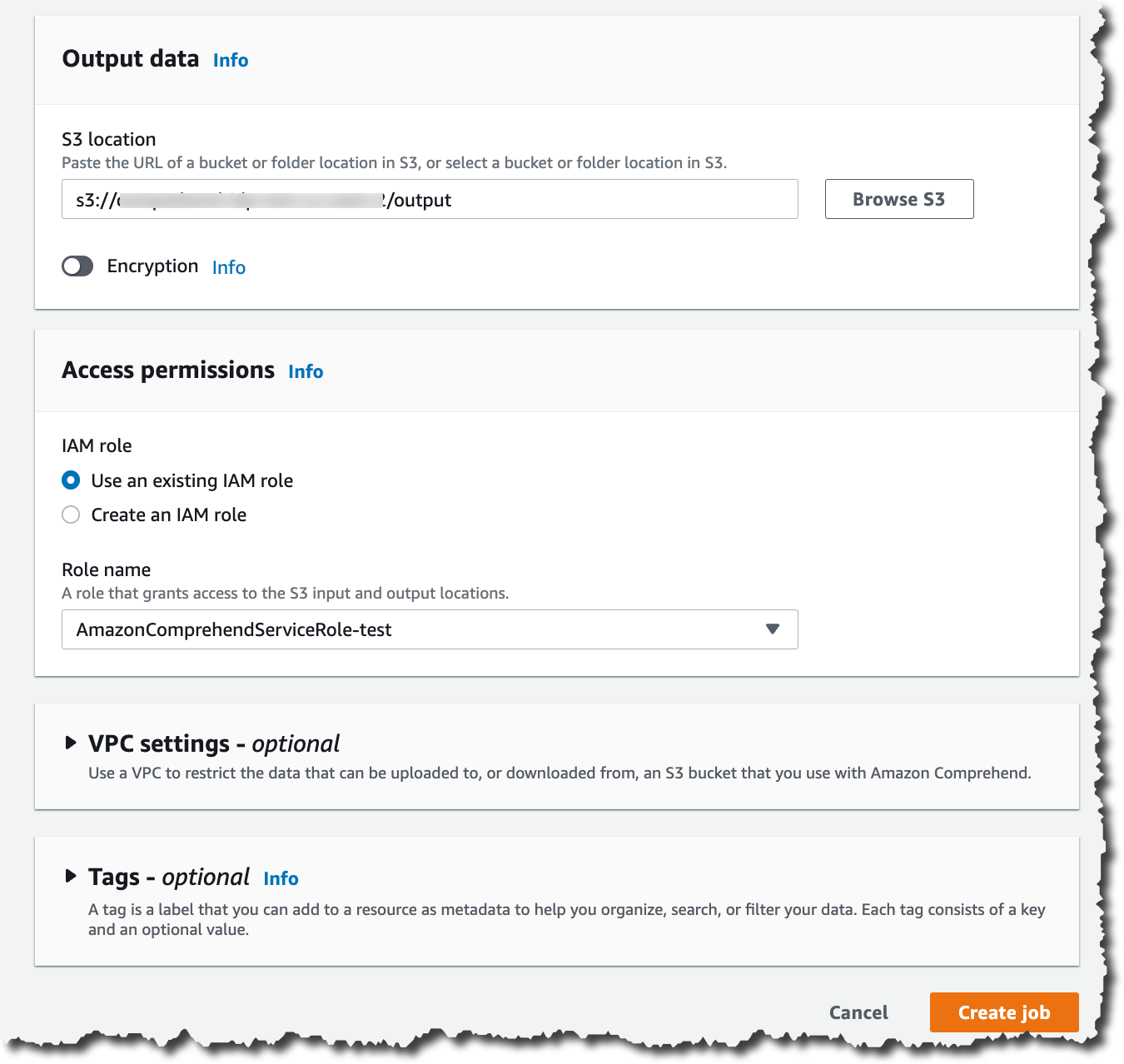
The job takes a few minutes to run, depending on the size of the input. When the job is ready, you can check the output results. You can find the results in the Amazon S3 location you specified when you created the job.
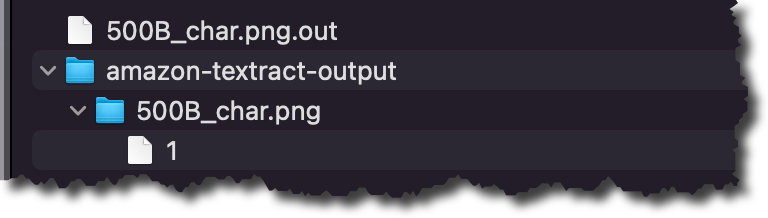
In the results folder, you will find a .out file for each of the semi-structured files Amazon Comprehend classified. The .out file is a JSON, in which each line represents a page of the document. In the amazon-textract-output directory, you will find a folder for each classified file, and inside that folder, there is one file per page from the original file. Those page files contain the classification results. To learn more about the outputs of the classifications, check the documentation page.
Available Now
You can get started classifying and extracting entities from semi-structured files like PDFs, images, and Word Documents asynchronously and synchronously today from Amazon Comprehend in all the Regions where Amazon Comprehend is available. Learn more about this new launch in the Amazon Comprehend Developer Guide.
— Marcia