|
Back in 1980, at my second professional programming job, I was working on a project that analyzed driver’s license data from a bunch of US states. At that time data of that type was generally stored in fixed-length records, with values carefully (or not) encoded into each field. Although we were given schemas for the data, we would invariably find that the developers had to resort to tricks in order to represent values that were not anticipated up front. For example, coding for someone with heterochromia, eyes of different colors. We ended up doing a full scan of the data ahead of our actual time-consuming and expensive analytics run in order to make sure that we were dealing with known data. This was my introduction to data quality, or the lack thereof.
AWS makes it easier for you to build data lakes and data warehouses at any scale. We want to make it easier than ever before for you to measure and maintain the desired quality level of the data that you ingest, process, and share.
Introducing AWS Glue Data Quality
Today I would like to tell you about AWS Glue Data Quality, a new set of features for AWS Glue that we are launching in preview form. It can analyze your tables and recommend a set of rules automatically based on what it finds. You can fine-tune those rules if necessary and you can also write your own rules. In this blog post I will show you a few highlights, and will save the details for a full post when these features progress from preview to generally available.
Each data quality rule references a Glue table or selected columns in a Glue table and checks for specific types of properties: timeliness, accuracy, integrity, and so forth. For example, a rule can indicate that a table must have the expected number of columns, that the column names match a desired pattern, and that a specific column is usable as a primary key.
Getting Started
I can open the new Data quality tab on one of my Glue tables to get started. From there I can create a ruleset manually, or I can click Recommend ruleset to get started:
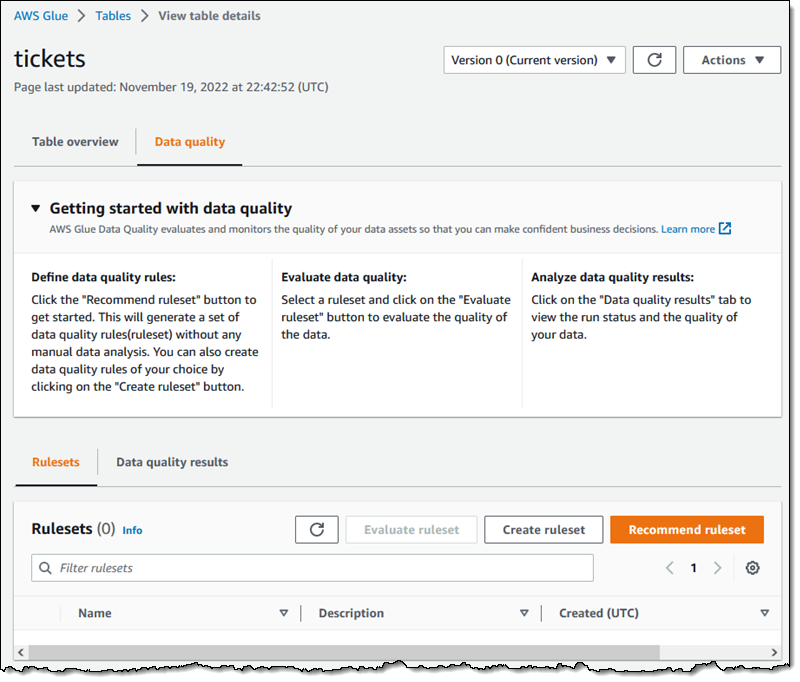
Then I enter a name for my Ruleset (RS1), choose an IAM Role that has permission to access it, and click Recommend ruleset:
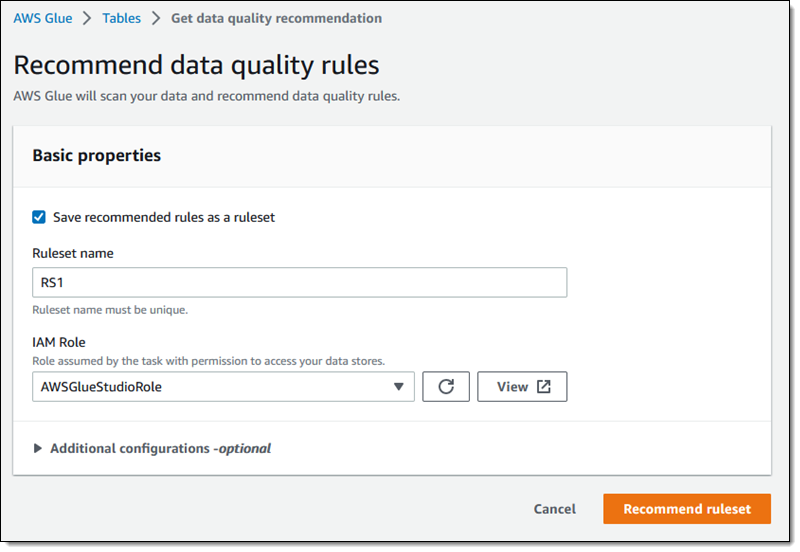
My click initiates a Glue Recommendation task (a specialized type of Glue job) that scans the data and makes recommendations. Once the task has run to completion I can examine the recommendations:

I click Evaluate ruleset to check on the quality of my data.
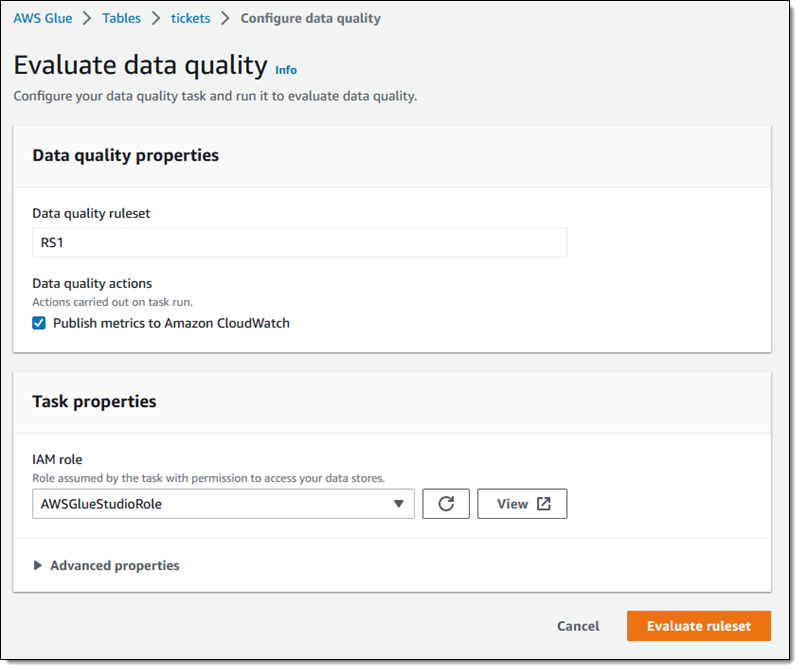
The data quality task runs and I can examine the results:
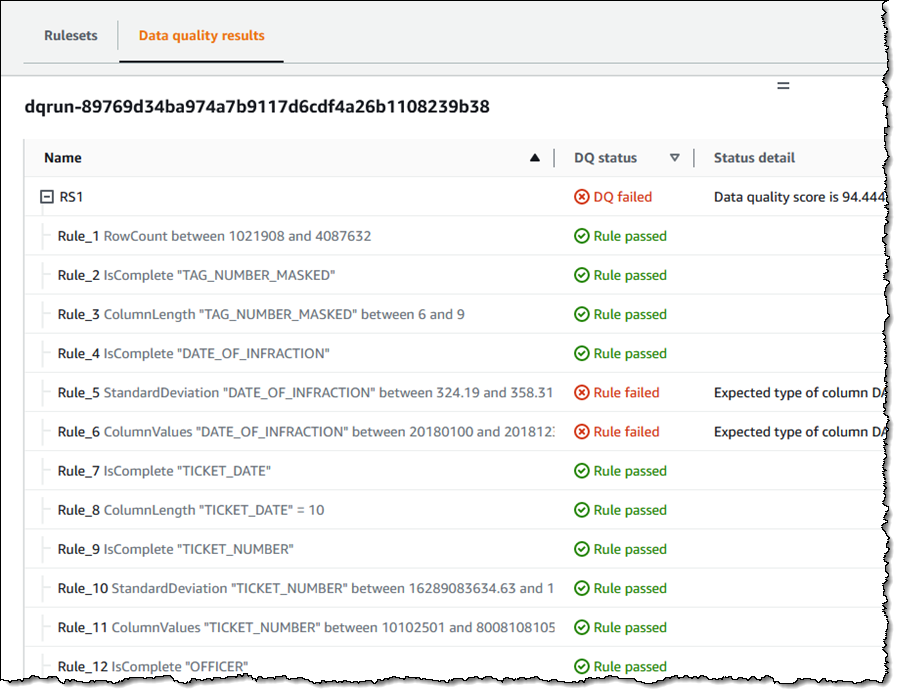
In addition to creating Rulesets that are attached to tables, I can use them as part of a Glue job. I create my job as usual and then add an Evaluate Data Quality node:

Then I use the Data Quality Definition Language (DDQL) builder to create my rules. I can choose between 20 different rule types:

For this blog post, I made these rules more strict than necessary so that I could show you what happens when the data quality evaluation fails.
I can set the job options, and choose the original data or the data quality results as the output of the transform. I can also write the data quality results to an S3 bucket:

After I have created my Ruleset, I set any other desired options for the job, save it, and then run it. After the job completes I can find the results in the Data quality tab. Because I made some overly strict rules, the evaluation correctly flagged my data with a 0% score:

There’s a lot more, but I will save that for the next blog post!
Things to Know
Preview Regions – This is an open preview and you can access it today the US East (Ohio, N. Virginia), US West (Oregon), Asia Pacific (Tokyo), and Europe (Ireland) AWS Regions.
Pricing – Evaluating data quality consumes Glue Data Processing Units (DPU) in the same manner and at the same per-DPU pricing as any other Glue job.
— Jeff;