
 |
Many of our customers are telling us they want to move away from commercial database vendors to avoid expensive costs and burdensome licensing terms. But migrating away from commercial and legacy databases can be time-consuming and resource-intensive. When migrating your databases, you can automate the migration of your database schema and data using the AWS Schema Conversation Tool and AWS Database Migration Service. But there is always more work to do to migrate the application itself, including rewriting application code that interacts with the database. Motivation is there, but costs and risks are often limiting factors.
Today, we are making Babelfish for Aurora PostgreSQL available. Babelfish allows Amazon Aurora PostgreSQL-Compatible Edition to understand the SQL Server wire protocol. It allows you to migrate your SQL Server applications to PostgreSQL cheaper, faster, and with less risks involved with such change.
You can migrate your application in a fraction of the time that a traditional migration would require. You continue to use the existing queries and drivers your application uses today. Just point the application to an Amazon Aurora PostgreSQL database with Babelfish activated. Babelfish adds the capability to Amazon Aurora PostgreSQL to understand the SQL Server wire protocol Tabular Data Stream (TDS), as well as extending PostgreSQL to understand commonly used T-SQL commands used by SQL Server. Support for T-SQL includes elements such as the SQL dialect, static cursors, data types, triggers, stored procedures, and functions. Babelfish reduces the risk associated with database migration projects by significantly reducing the number of changes required to the application. When adopting Babelfish, you save on licensing costs of using SQL Server. Amazon Aurora provides the security, availability, and reliability of commercial databases at 1/10th the cost.
SQL Server has evolved over more than 30 years, and we do not expect to support all functionalities right away. Instead, we focused on the most common T-SQL commands and returning the correct response or an error message. For example, the MONEY datatype has different characteristics in SQL Server (with four decimals precision) and PostgreSQL (with two decimals precision). Such a subtle difference might lead to rounding errors and have a significant impact on downstream processes, such as financial reporting. In this case, and many others, Babelfish ensures the semantics of SQL Server data types and T-SQL functionality are preserved: we created a MONEY datatype that behaves as SQL Server apps would expect. When you create a table with this datatype through the Babelfish connection, you get this compatible datatype and behaviors that a SQL Server app would expect.
Create a Babelfish Cluster Using the Console
To show you how Babelfish works, let’s first connect to the console and create a new Amazon Aurora PostgreSQL cluster. The procedure is no different than for the regular Amazon Aurora database. In the RDS launch wizard, I first make sure I select an Aurora version compatible with PostgreSQL 13.4, or more recent. The updated console has additional filters to help you select the versions that are compatible with Babelfish.
 Then, lower on the page, I select the option Turn on Babelfish.
Then, lower on the page, I select the option Turn on Babelfish.
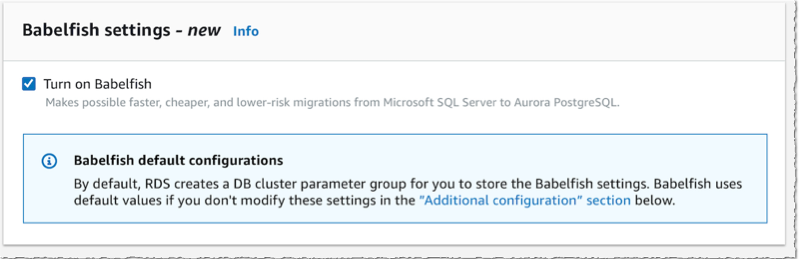
Under Monitoring section, I also make sure I turn off Enable Enhanced monitoring. This option requires additional IAM permissions and preparation that are not relevant for this demo.
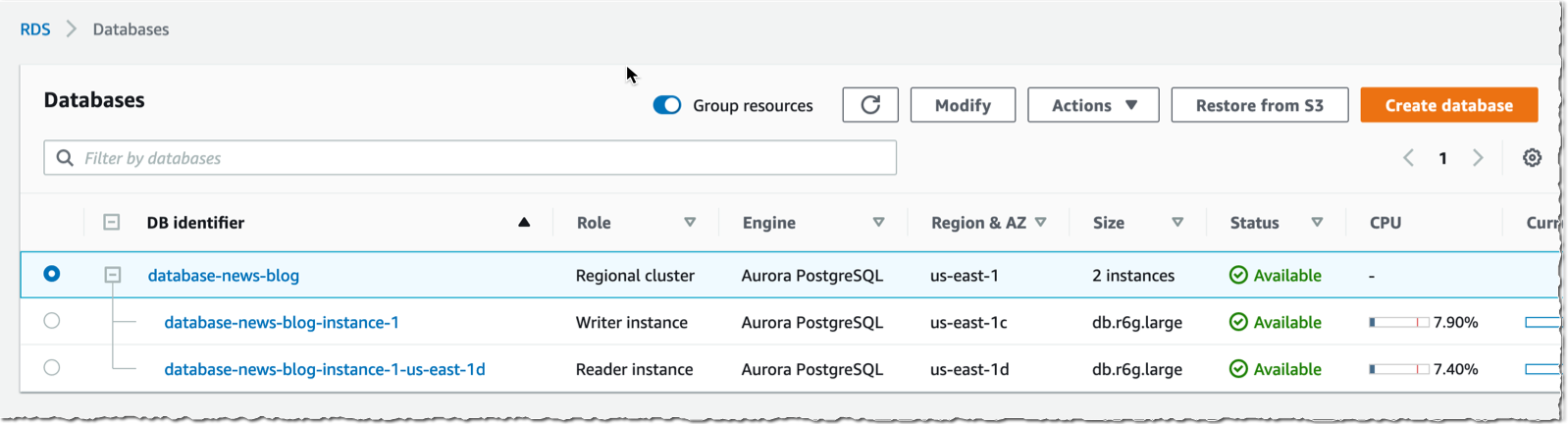
 After a couple of minutes, my cluster is created, it has two instances, one writer and one reader.
After a couple of minutes, my cluster is created, it has two instances, one writer and one reader.
Create a Babelfish Cluster Using the CLI
Alternatively, I may use the CLI to create a cluster. I first create a parameter group to activate Babelfish (the console does it automatically):
aws rds create-db-cluster-parameter-group –db-cluster-parameter-group-name myapp-babelfish –db-parameter-group-family aurora-postgresql13 –description “babelfish APG 13” aws rds modify-db-cluster-parameter-group –db-cluster-parameter-group-name myapp-babelfish –parameters “ParameterName=rds.babelfish_status,ParameterValue=on,ApplyMethod=pending-reboot”
Then I create the database cluster (when using the command below, adjust the security group id and the subnet group name) :
aws rds create-db-cluster –db-cluster-identifier awsnewblog-cli-demo –master-username postgres –master-user-password Passw0rd –engine aurora-postgresql –engine-version 13.4 –vpc-security-group-ids sg-abcd1234 –db-subnet-group-name default-vpc-1234abcd –db-cluster-parameter-group-name myapp-babelfish { “DBCluster”: { “AllocatedStorage”: 1, “AvailabilityZones”: [ “us-east-1c”, “us-east-1d”, “us-east-1a” ], “BackupRetentionPeriod”: 1, “DBClusterIdentifier”: “awsnewblog-cli-demo”, “Status”: “creating”, …
Once the cluster is created, I create an instance using
aws rds create-db-instance –db-instance-identifier myapp-db1 –db-instance-class db.r5.4xlarge –db-subnet-group-name default-vpc-1234abcd –db-cluster-identifier awsnewblog-cli-demo –engine aurora-postgresql { “DBInstance”: { “DBInstanceIdentifier”: “myapp-db1”, “DBInstanceClass”: “db.r5.4xlarge”, “Engine”: “aurora-postgresql”, “DBInstanceStatus”: “creating”, …
Connect to the Babelfish Cluster
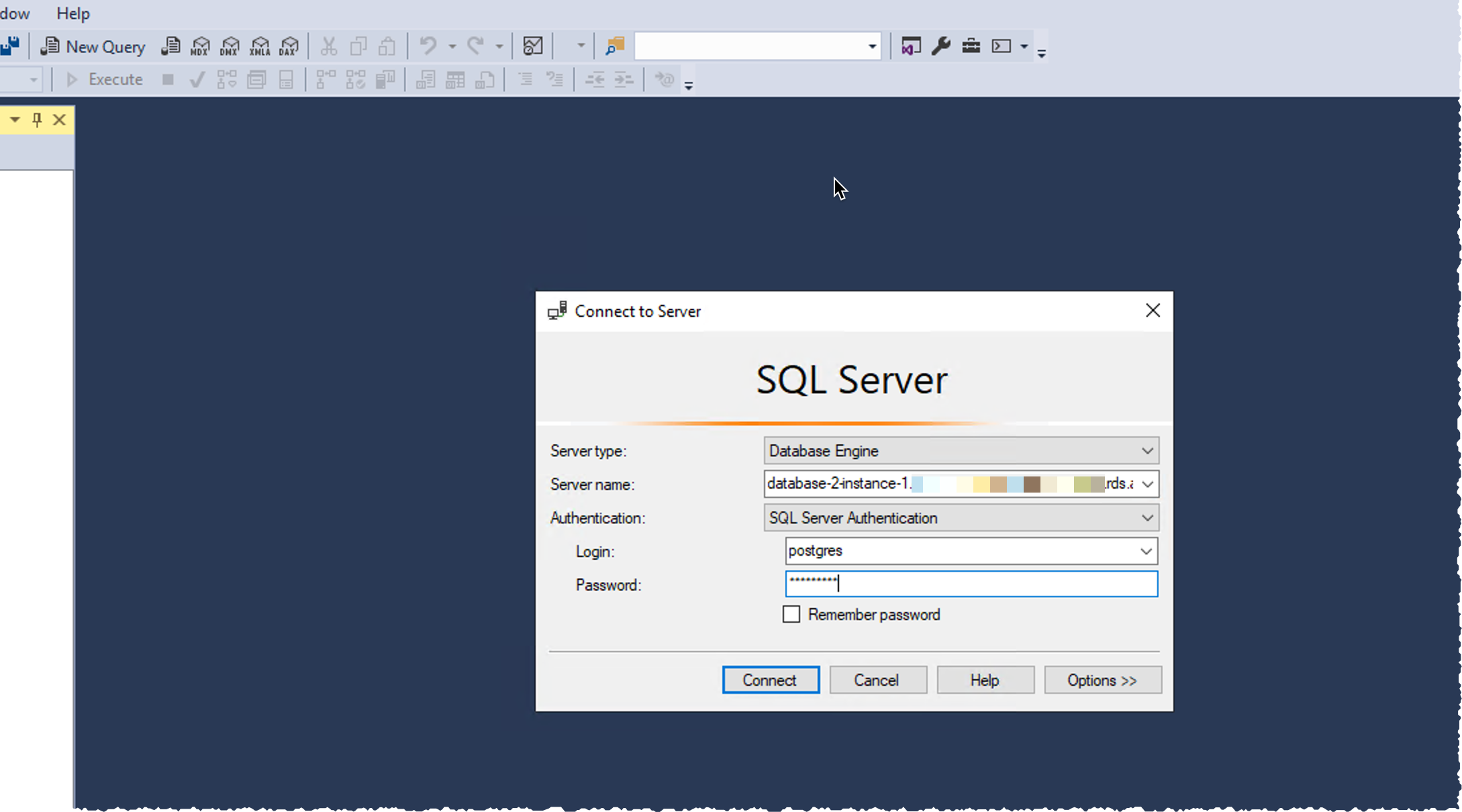
Once the cluster and instances are ready, I connect to the writer instance to create the database itself. I may connect to the instance using SQL Server Management Studio (SSMS) or other SQL client such as sqlcmd. The Windows client must be able to connect to the Babelfish cluster, I made sure the RDS security group authorizes connections from the Windows host.
Using SSMS on Windows, I select New Query in the toolbar, I enter the database DNS name as Server name. I select SQL Server Authentication and I enter the database Login and Password. I click on Connect.
Important: Do not connect via the SSMS Object Explorer. Be sure to connect using the query editor via the New Query button. At this time, Babelfish supports the query editor, but not the Object Explorer.
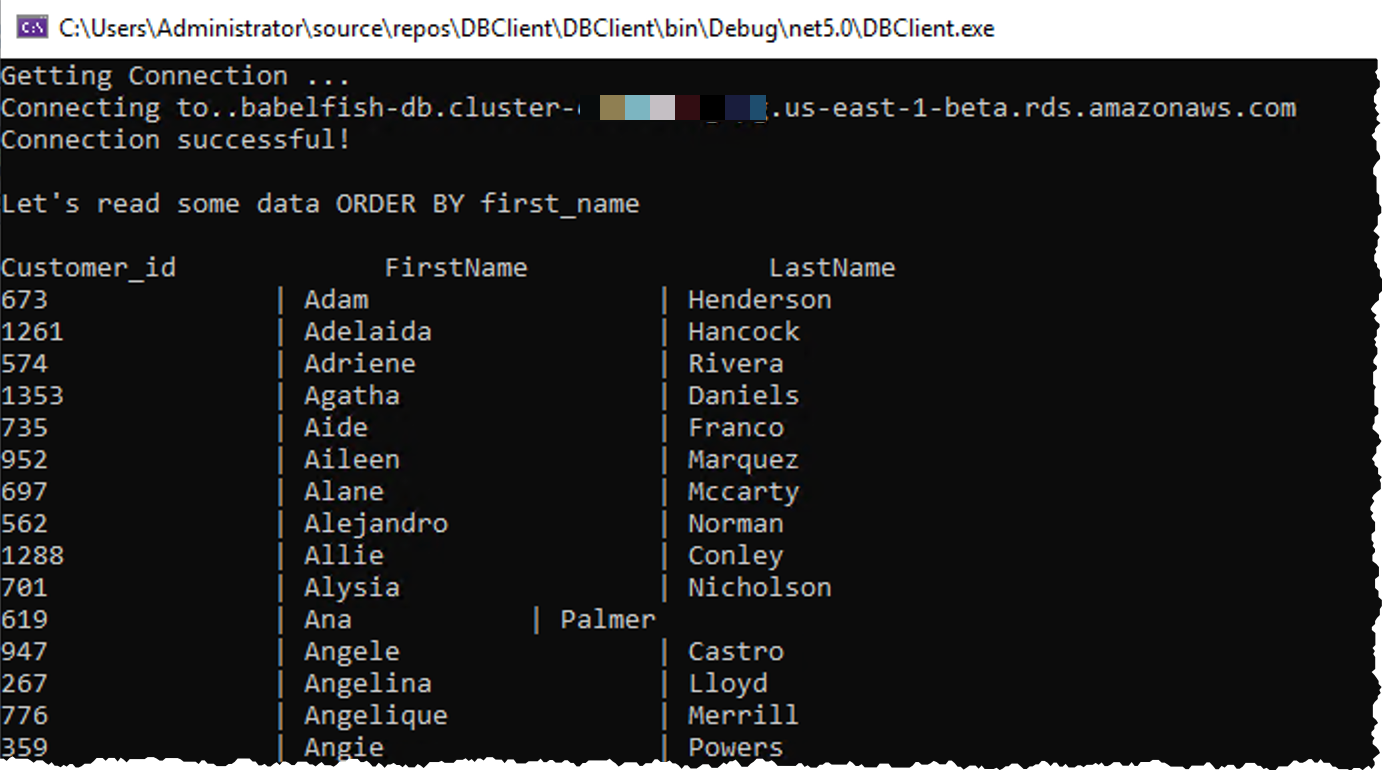
Once connected, I check the version with select @@version statement and click the green Execute button in the toolbar. I can read the statement result on the bottom part of the screen.

Finally, I create the database on the instance with the create database demo statement.

By default, Babelfish runs in single-db mode. Using this mode, you can have maximum one user database per instance. It allows to have a close mapping of schema names between SQL Server and PostgreSQL. Alternatively, you may turn on multi-db mode at cluster creation time. This allows you to create multiple user databases per instance. In PostgreSQL, user databases will be mapped to multiple schemas with the database name as a prefix.
Run an Application
For the purpose of this demo, I use a database schema provided by SQLServerTutorial.net as part of their SQL Server Tutorial to create a schema and populate it with data. The SQL script and application C# code I use in this demo are available on my GitHub repository. A big thanks to my colleague Anuja for providing me with a C# demo application.
In SQL Server Management Studio, I open the create_objects.sql script and I choose the green execute icon on the top toolbar. A confirmation message tells me the database schema is created.

I repeat the operation with the load_data.sql script to load data in the newly created tables. Data loading takes a few minutes to run.
Now the database is loaded, let’s open Anuja‘s C# application developed to access a SQL Server database. I modify two lines of code:
- line 12 : I type the DNS name of the Babelfish cluster I created earlier. Note that I use the DNS name of a “write” node from my cluster.
- line 15 : I type the password I entered when I created the database cluster.

And that’s it! No other modification is required on this app. This code written to query and interact with SQL Server is just working “as-is” on Aurora PostgreSQL with Babelfish.
Open Source Transparency
We decided to open-source the technology behind Babelfish to create the Babelfish for PostgreSQL open source project. It uses the permissive Apache 2.0 and PostgreSQL licenses, meaning you can modify or tweak or distribute Babelfish in whatever fashion you see fit. Over time, we are shifting Babelfish to fully open development on GitHub, so there is transparency from the start. Now, anyone, whether you are an AWS customer or not, can use Babelfish to leave behind SQL Server and quickly, easily, and cost-effectively migrate your applications to open source PostgreSQL. We believe Babelfish is going to make PostgreSQL accessible to a much wider group of customers and developers than ever before, particularly those with large numbers of complex applications originally written for SQL Server.
Availability
Babelfish for Aurora PostgreSQL is available today in all publicly available AWS Regions at no additional cost. Start your application migration today.
PS : if you wonder where the name Babelfish comes from, just remember the answer is 42. (Or you can read this slightly longer answer.)

