
 |
Back in 2019 I told you about AWS Data Exchange and showed you how to Find, Subscribe To, and Use Data Products. Today, you can choose from over 3600 data products in ten categories:

In my introductory post I showed you how could subscribe to data products and then download the data sets into an Amazon Simple Storage Service (Amazon S3) bucket. I then suggested various options for further processing, including AWS Lambda functions, a AWS Glue crawler, or an Amazon Athena query.
Today we are making it even easier for you to find, subscribe to, and use third-party data with the introduction of AWS Data Exchange for Amazon Redshift. As a subscriber, you can directly use data from providers without any further processing, and no need for an Extract Transform Load (ETL) process. Because you don’t have to do any processing, the data is always current and can be used directly in your Amazon Redshift queries. AWS Data Exchange for Amazon Redshift takes care of managing all entitlements and payments for you, with all charges billed to your AWS account.
As a provider, you now have a new way to license your data and make it available to your customers.
As I was writing this post, it was cool to realize just how many existing aspects of Redshift, and Data Exchange played central roles. Because Redshift has a clean separation of storage and compute, along with built-in data sharing features, the data provider allocates and pays for storage, and the data subscriber does the same for compute. The provider does not need to scale their cluster in proportion to the size of their subscriber base, and can focus on acquiring and providing data.
Let’s take a look at this feature from two vantage points: subscribing to a data product, and publishing a data product.
AWS Data Exchange for Amazon Redshift – Subscribing to a Data Product
As a data subscriber I can browse through the AWS Data Exchange catalog and find data products that are relevant to my business, and subscribe to them.
Data providers can also create private offers and extend them to me for access via the AWS Data Exchange Console. I click My product offers, and review the offers that have been extended to me. I click on Continue to subscribe to proceed:

Then I complete my subscription by reviewing the offer and the subscription terms, noting the data sets that I will get, and clicking Subscribe:
Once the subscription is completed, I am notified and can move forward:
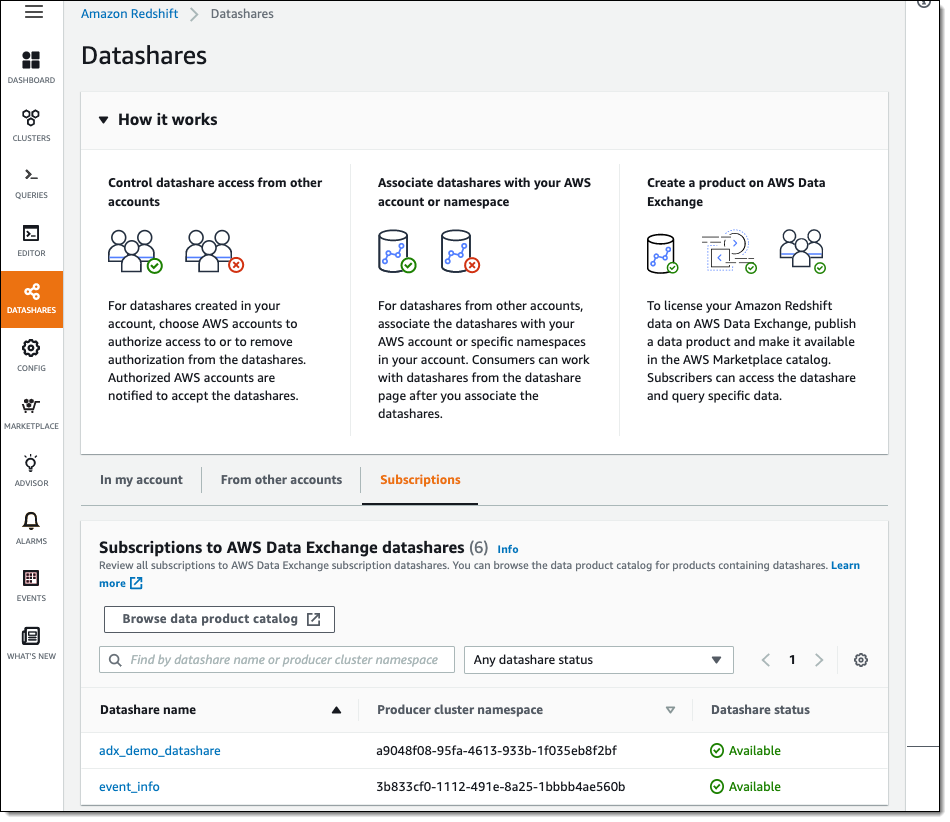
From the Redshift Console, I click Datashares, select Subscriptions, and I can see the subscribed data set:
Next, I associate it with one or more of my Redshift clusters by creating a database that points to the subscribed datashare, and use the tables, views, and stored procedures to power my Redshift queries and my applications.
AWS Data Exchange for Amazon Redshift – Publishing a Data Product
As a data provider I can include Redshift tables, views, schemas and user-defined functions in my AWS Data Exchange product. To keep things simple, I’ll create a product that includes just one Redshift table.
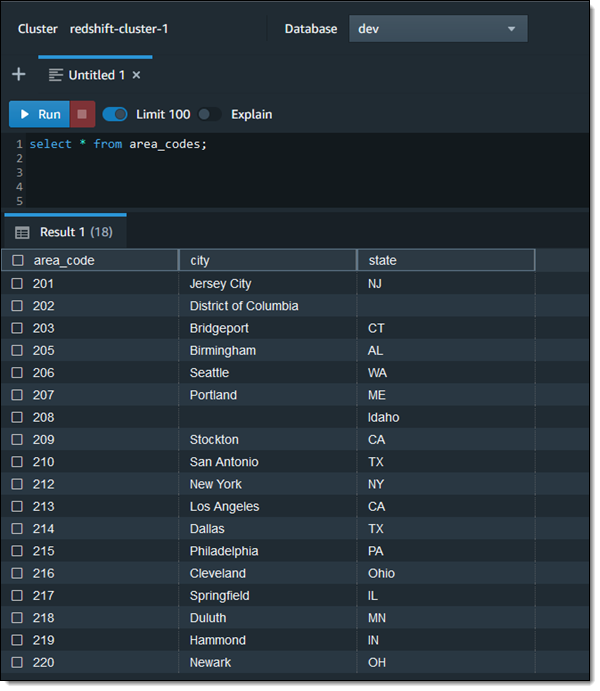
I use the spiffy new Redshift Query Editor V2 to create a table that maps US area codes to a city and a state:
Then I examine the list of existing datashares for my Redshift cluster, and click Create datashare to make a new one:
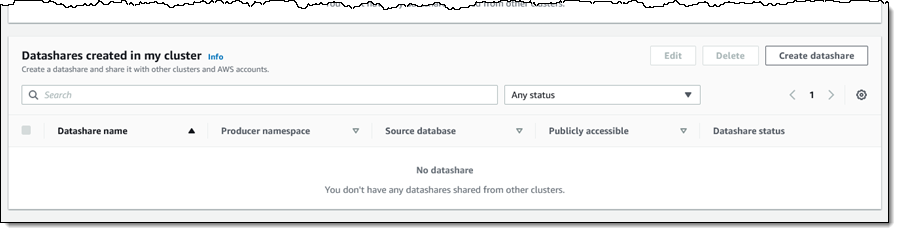
Next, I go through the usual process for creating a datashare. I select AWS Data Exchange datashare, assign a name (area_code_reference), pick the database within the cluster, and make the datashare accessible to publicly accessible clusters:
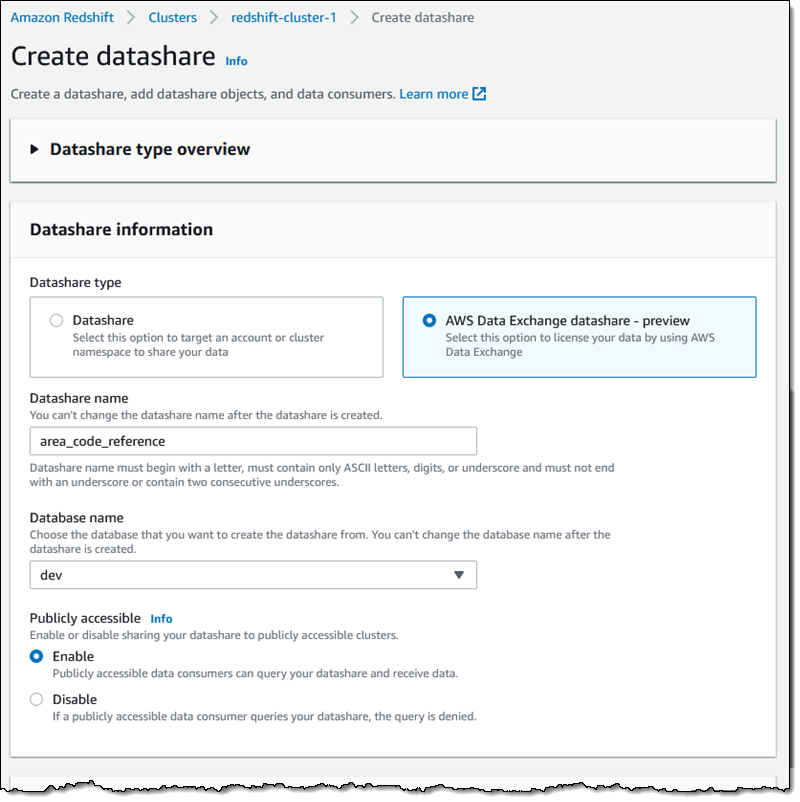
Then I scroll down and click Add to move forward:

I choose my schema (public), opt to include only tables and views in my datashare, and then add the area_codes table:
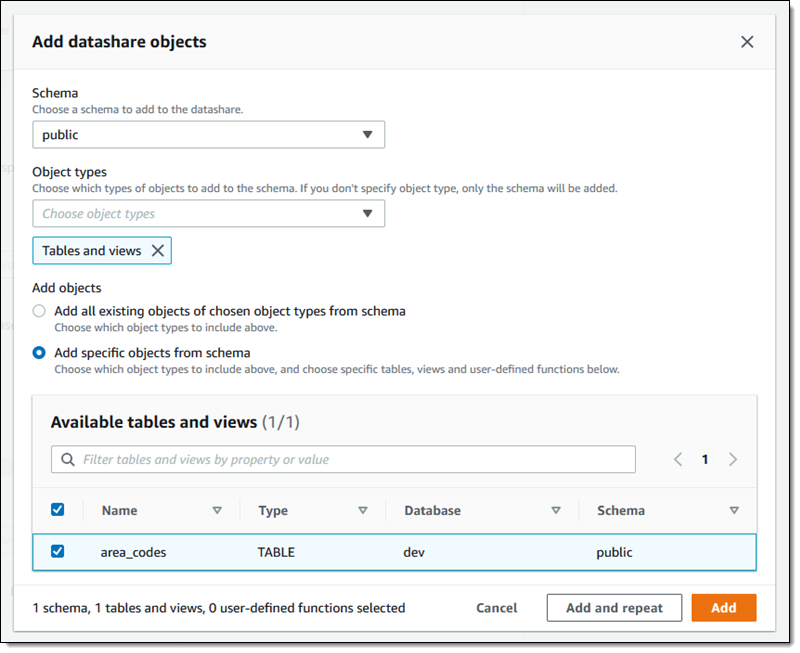
At this point I can click Add to wrap up, or Add and repeat to make a more complex product that contains additional objects.
I confirm that the datashare contains the table, and click Create datashare to move forward:
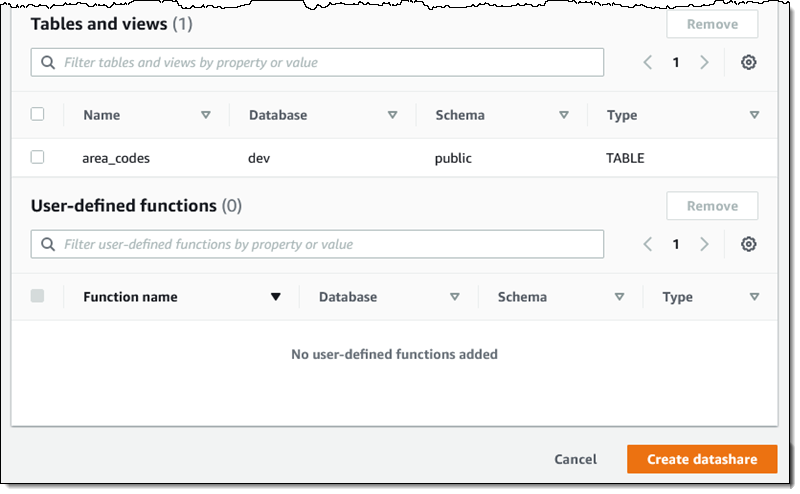
Now I am ready to start publishing my data! I visit the AWS Data Exchange Console, expand the navigation on the left, and click Owned data sets:

I review the Data set creation steps, and click Create data set to proceed:
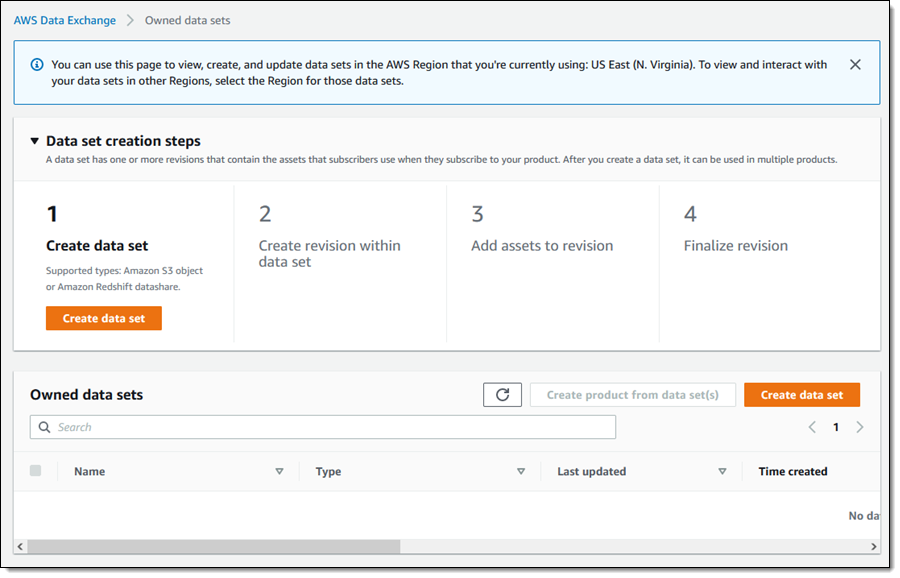
I select Amazon Redshift datashare, give my data set a name (United States Area Codes), enter a description, and click Create data set to proceed:
I create a revision called v1:

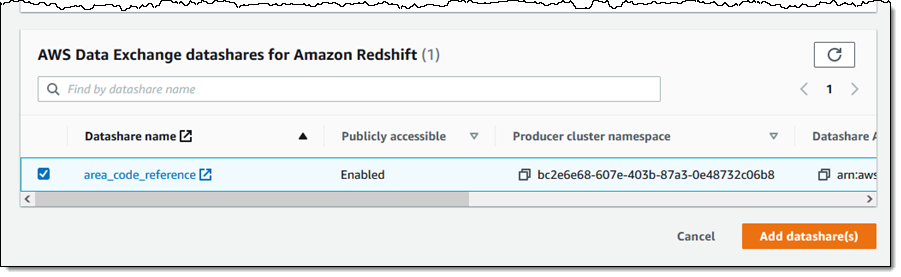
I select my datashare and click Add datashare(s):
Then I finalize the revision:

I showed you how to create a datashare and a dataset, and to publish a product using the console. If you are publishing multiple products and/or making regular revisions, you can automate all of these steps using the AWS Command Line Interface (CLI) and the Amazon Data Exchange APIs.
Initial Data Products
Multiple data providers are working to make their data products available to you through AWS Data Exchange for Amazon Redshift. Here are some of the initial offerings and the official descriptions:
- FactSet Supply Chain Relationships – FactSet Revere Supply Chain Relationships data is built to expose business relationship interconnections among companies globally. This feed provides access to the complex networks of companies’ key customers, suppliers, competitors, and strategic partners, collected from annual filings, investor presentations, and press releases.
- Foursquare Places 2021: New York City Sample – This trial dataset contains Foursquare’ss integrated Places (POI) database for New York City, accessible as a Redshift Data Share. Instantly load Foursquare’s Places data in to a Redshift table for further processing and analysis. Foursquare data is privacy-compliant, uniquely sourced, and trusted by top enterprises like Uber, Samsung, and Apple.
- Mathematica Medicare Pilot Dataset – Aggregate Medicare HCC counts and prevalence by state, county, payer, and filtered to the diabetic population from 2017 to 2019.
- COVID-19 Vaccination in Canada – This listing contains sample datasets for COVID-19 Vaccination in Canada data.
- Revelio Labs Workforce Composition and Trends Data (Trial data) – Understand the workforce composition and trends of any company.
- Facteus – US Card Consumer Payment – CPG Backtest – Historical sample from panel of SKU-level transaction detail from cash and card transactions across hundreds of Consumer-Packaged Goods sold at over 9,000 urban convenience stores and bodegas across the U.S.
- Decadata Argo Supply Chain Trial Data – Supply chain data for CPG firms delivering products to US Grocery Retailers.
— Jeff;

